scATAC-seq 多样本整合分析教程 (Signac / LSI)
环境准备
R 包加载
请选择 common_r 这个环境进行该整合教程的学习
#加载必要的R包
suppressPackageStartupMessages({
library(Seurat)
library(Signac)
library(EnsDb.Hsapiens.v86, lib.loc = "/PROJ2/FLOAT/shumeng/apps/miniconda3/envs/python3.10/lib/R/library")
library(BSgenome.Hsapiens.UCSC.hg38,lib = "/PROJ2/FLOAT/shumeng/apps/miniconda3/envs/python3.10/lib/R/library")
library(biovizBase, lib = "/PROJ2/FLOAT/shumeng/apps/miniconda3/envs/python3.10/lib/R/library")
#library(BSgenome.Mmusculus.UCSC.mm10)
#library(EnsDb.Mmusculus.v79)
library(dplyr)
library(ggplot2)
library(patchwork)
library(harmony)
})
# 设置随机种子
set.seed(1234)
# 注意,如果数据较大,可以自定义设置资源
options(future.globals.maxSize = 15 * 1024^3) # 15GBmy36colors <-c( '#E5D2DD', '#53A85F', '#F1BB72', '#F3B1A0', '#D6E7A3', '#57C3F3', '#476D87',
'#E95C59', '#E59CC4', '#AB3282', '#23452F', '#BD956A', '#8C549C', '#585658',
'#9FA3A8', '#E0D4CA', '#5F3D69', '#C5DEBA', '#58A4C3', '#E4C755', '#F7F398',
'#AA9A59', '#E63863', '#E39A35', '#C1E6F3', '#6778AE', '#91D0BE', '#B53E2B',
'#712820', '#DCC1DD', '#CCE0F5', '#CCC9E6', '#625D9E', '#68A180', '#3A6963',
'#968175', "#6495ED", "#FFC1C1",'#f1ac9d','#f06966','#dee2d1','#6abe83','#39BAE8','#B9EDF8','#221a12',
'#b8d00a','#74828F','#96C0CE','#E95D22','#017890')获取基因注释信息
我们将从 EnsDb 数据库获取相应物种的基因组注释信息(基因位置、转录本、外显子、TSS 等),具体物种需根据数据做更换。这些信息用于:
- 计算 ATAC 的 TSS 富集(判断开放染色质是否在转录起始位点附近更集中)
- 构建基因活性矩阵(把 peaks 信号映射到基因上)
- Peak 注释和功能分析
注意事项:
- 物种与参考基因组版本匹配(如
EnsDb.Hsapiens.v86对应 hg38,EnsDb.Mmusculus.v75对应 mm10) - 染色体命名风格一致(例如都用
chr1、chr2这样的前缀)
# 本教程使用的是人的数据,因此获取基因注释信息
suppressWarnings({
suppressMessages({
annotation <- GetGRangesFromEnsDb(ensdb = EnsDb.Hsapiens.v86)
seqlevels(annotation) <- paste0('chr', seqlevels(annotation))
genome(annotation) <- 'hg38'
})
})
# 设置并行计算(静默处理,可选)
suppressPackageStartupMessages({
library(future)
})
plan("multicore", workers = 4)数据读取
本教程提供两种不同形式的数据输入方式,以满足不同用户的数据获取需求,选择适合自己的一种方式即可:
云平台 RDS 文件读取
数据特点:
- RDS 文件是标准的 Seurat 对象文件
- 数据已经过预处理和多个样本合并
- 可直接用于后续的下游分析,也可以提取表达矩阵,重新整合
适用场景:
- 当您无法获得标准的
filtered_peaks_bc_matrix表达矩阵和 fragment 矩阵时 - 希望整合云平台现有数据进行学习时
- 需要快速重新进行 scRNA-seq 数据整合分析时
注意事项:
- 具体挂载数据和 rds 文件的读取,请参照 jupyter 使用教程
例如下列项目数据/home/demo-SeekGene-com/workspace/data/AY1752565399550/
library(Seurat)
library(Signac)
# 1. 读取数据
input <- readRDS("/home/demo-seekgene-com/workspace/data/AY1752565399550/input.rds")
meta <- read.table("/home/demo-seekgene-com/workspace/data/AY1752565399550/meta.tsv",
header = TRUE,
sep = "\t",
row.names = 1)
# 2. 提取 ATAC 数据和基因组注释
counts <- input@assays$ATAC@counts # ATAC 计数矩阵
fragments <- input@assays$ATAC@fragments # 片段文件(如果有)
annotations <- input@assays$ATAC@annotation # 基因组注释
# 3. 创建 ChromatinAssay(Signac 格式的 ATAC 数据)
atac_assay <- CreateChromatinAssay(
counts = counts,
fragments = fragments,
annotation = annotations
)
# 4. 创建 Seurat 对象(仅包含 ATAC 数据)
atac_seurat <- CreateSeuratObject(
counts = atac_assay, # 使用 ChromatinAssay 作为输入
assay = "ATAC", # 指定 assay 名称
meta.data = meta # 添加样本元数据
)
seurat_list <- SplitObject(atac_seurat, split.by = "Sample")
# 6. 清理内存
rm(input, counts, fragments, annotations, atac_assay)
gc()标准 filtered_peaks_bc_matrix 文件读取
适用场景:
- 当您拥有标准的基因表达矩阵和 epaks 开放矩阵文件时
- 希望自主完成单细胞多组学(SeekArc)数据的多样本整合和批次矫正时
- 需要进行完整的从原始数据到整合分析的工作流程时
注意:
- 请保证样本与样本之间的文件结构如下:
数据目录结构需满足如下要求:
- 每个样本的文件夹名称为样本 ID,如 S127、S44R 等。
- 每个样本文件夹下包含以下文件:
filtered_peaks_bc_matrix:ATAC 的 peak 开放矩阵文件夹,包含barcodes.tsv.gz、features.tsv.gz和matrix.mtx.gz文件。{样本 ID}_A_fragments.tsv.gz:ATAC 片段文件,如 S127_A_fragments.tsv.gz。{样本 ID}_A_fragments.tsv.gz.tbi:ATAC 片段索引文件,如 S127_A_fragments.tsv.gz.tbi。
具体文件夹结构如下:
scATAC-seq 数据(peaks 矩阵 + 片段)
├── S127/
│ ├── filtered_peaks_bc_matrix/
│ │ ├── barcodes.tsv.gz(细胞条形码)
│ │ ├── features.tsv.gz(peaks 列表)
│ │ └── matrix.mtx.gz(稀疏计数矩阵)
│ ├── S127_A_fragments.tsv.gz(每条测序读段的基因组坐标)
│ ├── S127_A_fragments.tsv.gz.tbi(fragments 的索引文件)
│ └── per_barcode_metrics.csv(可选,每细胞质控指标)
├── S44R/
│ ├── filtered_peaks_bc_matrix/
│ │ ├── barcodes.tsv.gz
│ │ ├── features.tsv.gz
│ │ └── matrix.mtx.gz
│ ├── S44R_A_fragments.tsv.gz
│ ├── S44R_A_fragments.tsv.gz.tbi
│ └── per_barcode_metrics.csv(可选)
# 定义样本名称
sample_names <- c('S127', 'S44R')
# 创建一个空的list来存储每个样本的Seurat对象
seurat_list <- list()
for (sample in sample_names) {
cat('正在处理样本:', sample, '\n')
# 构建文件路径
counts_path <- file.path(sample, 'filtered_peaks_bc_matrix')
fragments_path <- file.path(sample, paste0(sample, '_A_fragments.tsv.gz'))
#metadata_path <- file.path(sample, 'per_barcode_metrics.csv')
# 读取peaks矩阵数据
counts <- Read10X(counts_path)
# 读取质控指标metadata
#metadata <- read.csv(
# file = metadata_path,
# header = TRUE,
# row.names = 1
#)
# 创建ChromatinAssay对象
chrom_assay <- CreateChromatinAssay(
counts = counts,
sep = c(":", "-"),
fragments = fragments_path,
min.cells = 3,
min.features = 200
)
# 创建Seurat对象
obj <- CreateSeuratObject(
counts = chrom_assay,
assay = "ATAC"#,meta.data = metadata
)
# 添加基因注释信息
Annotation(obj) <- annotation
# 添加样本标识
obj$Sample <- sample
obj$orig.ident <- sample
# 将Seurat对象添加到list中
seurat_list[[sample]] <- obj
cat('样本', sample, '处理完成,细胞数量:', ncol(obj), '\n')
}质量控制
质控指标计算
scATAC-seq 常用 QC 指标:
TSS.enrichment(TSS 富集分数,通常>2):越高越好,说明信号在转录起始位点附近更集中;过低可能提示背景高或细胞活性差。nucleosome_signal(核小体信号,越低越好):反映核小体周期性信号;通常越低越好。blacklist_ratio(黑名单区域比例):落在基因组黑名单区域的 reads 比例;过高提示数据质量问题。nCount_ATAC:总 ATAC 计数,极低或极高都需警惕异常。
实际阈值应基于数据分布设置,并与 fragments 质量、双细胞比例等因素结合判断。
# 对每个样本进行质量控制
suppressWarnings({
suppressMessages({
for (sample_name in names(seurat_list)) {
seurat_obj <- seurat_list[[sample_name]]
# 设置默认assay为ATAC
DefaultAssay(seurat_obj) <- 'ATAC'
# 计算TSS富集分数
seurat_obj <- TSSEnrichment(seurat_obj)
# 计算核小体信号
seurat_obj <- NucleosomeSignal(seurat_obj)
# 计算黑名单区域读取比例
seurat_obj$blacklist_ratio <- FractionCountsInRegion(
object = seurat_obj,
assay = 'ATAC',
regions = blacklist_hg38_unified)
# 更新seurat_list中的对象
seurat_list[[sample_name]] <- seurat_obj
}
})
})Extracting fragments at TSSs
Computing TSS enrichment score
Extracting TSS positions
Extracting fragments at TSSs
Computing TSS enrichment score
质控指标可视化
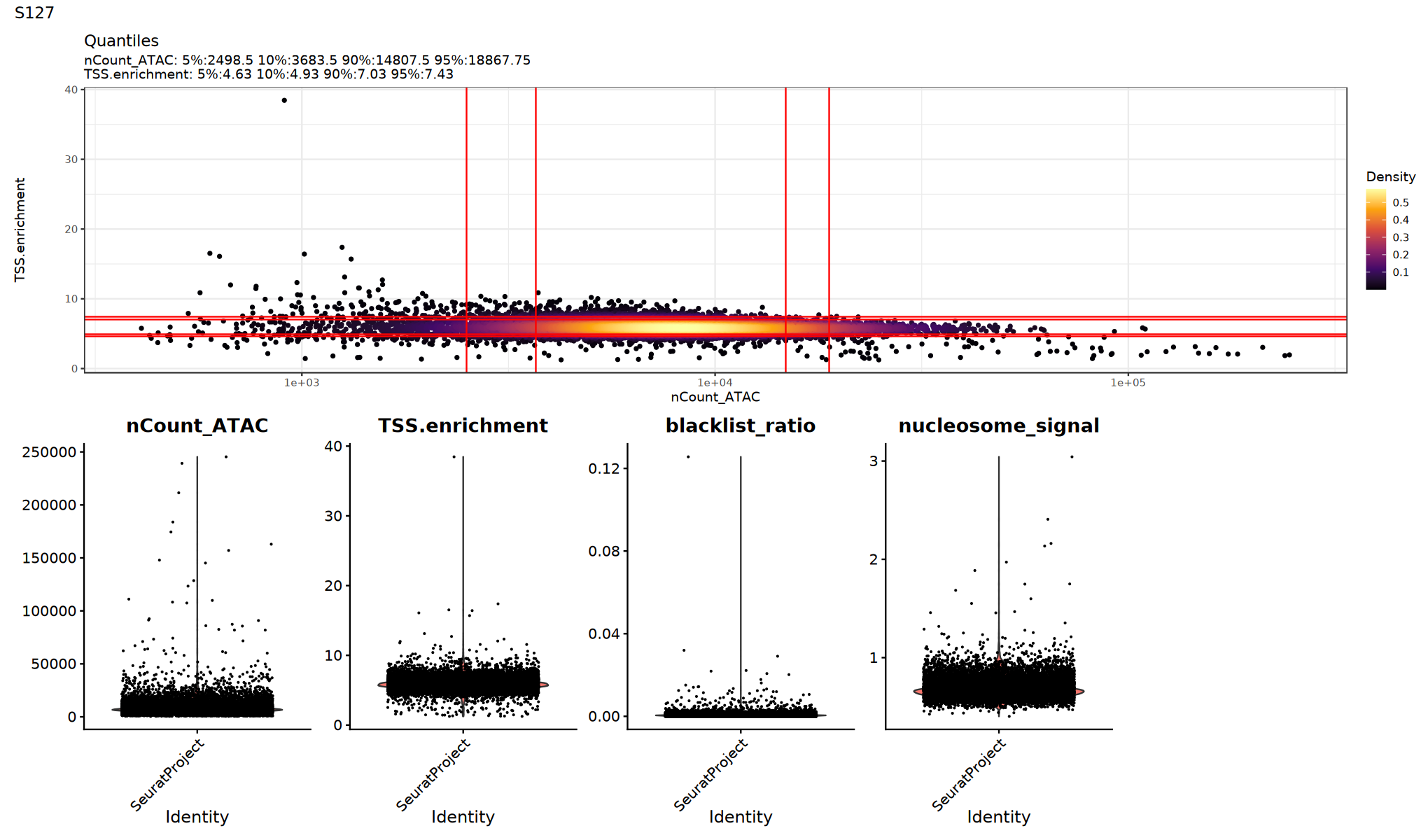
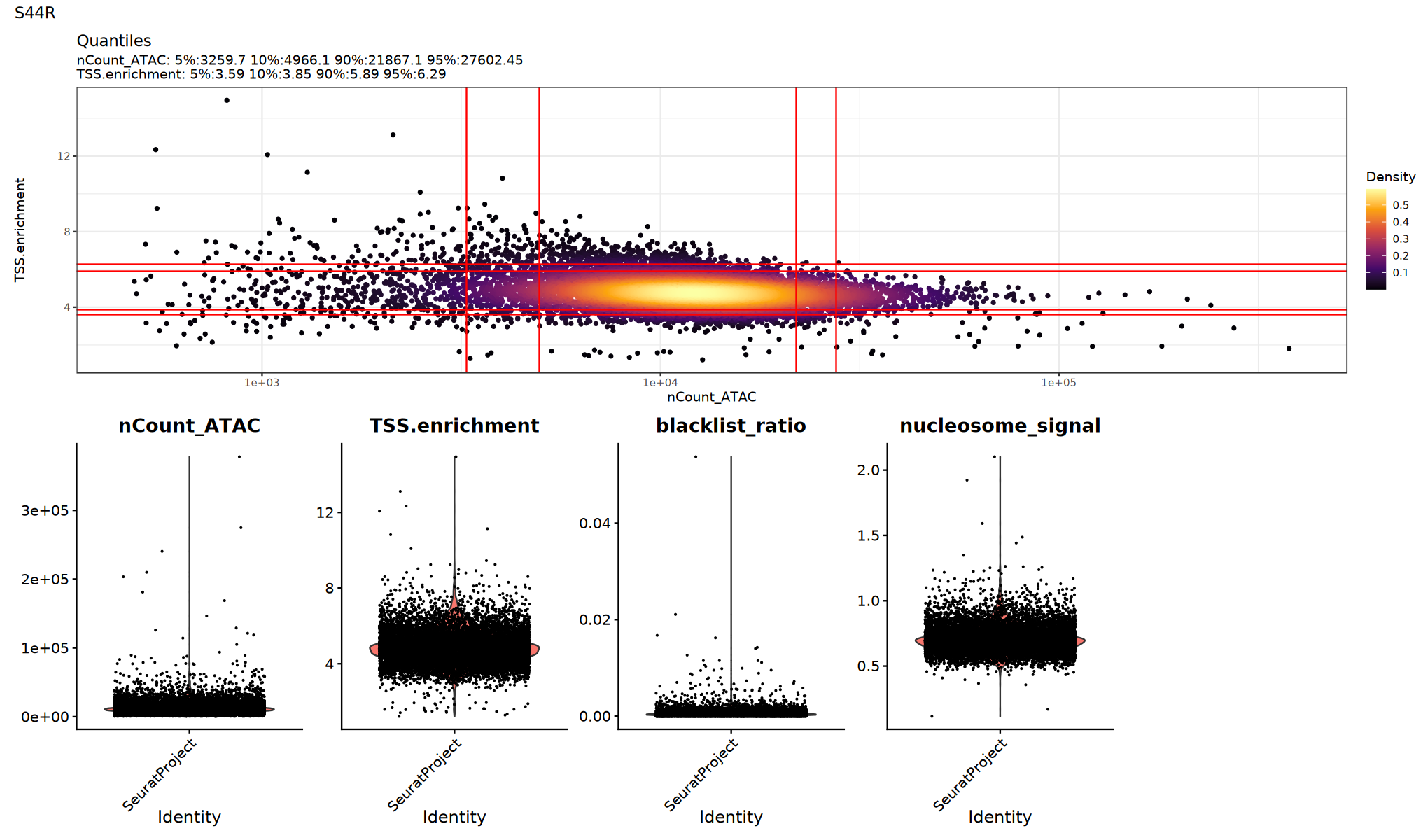
用小提琴图查看各 QC 指标的分布/异常点,确定合适的阈值:
建议:
- 观察是否存在明显的长尾或双峰分布
- 尝试多组阈值并比较下游聚类/UMAP 是否更清晰
# 可视化各质控指标,该cell内容选择性执行,非必要
options(repr.plot.width = 17, repr.plot.height = 10)
suppressWarnings({
for (sample_name in names(seurat_list)) {
seurat_obj <- seurat_list[[sample_name]]
p1=DensityScatter(seurat_obj, x = 'nCount_ATAC', y = 'TSS.enrichment', log_x = TRUE, quantiles = TRUE)
p2=VlnPlot(
object = seurat_obj,
features = c('nCount_ATAC', 'TSS.enrichment', 'blacklist_ratio', 'nucleosome_signal'),
pt.size = 0.1,
ncol = 5
)
print(p1 / p2 + plot_annotation(title = sample_name))
}
})
低质量细胞过滤
根据质控指标过滤低质量细胞。具体阈值应根据数据特征进行调整。具体过滤阈值参考上面的小提琴图分布情况。
# 设置质控过滤阈值(具体阈值根据数据特征进行调整)
for (sample_name in names(seurat_list)) {
cat('正在对样本', sample_name, '进行质控过滤...\n')
seurat_obj <- seurat_list[[sample_name]]
# 记录过滤前的细胞数量
cells_before <- ncol(seurat_obj)
# 根据质控指标进行过滤
seurat_obj <- subset(
x = seurat_obj,
subset = nCount_ATAC > 500 &
nCount_ATAC < 100000 &
blacklist_ratio < 0.05 &
nucleosome_signal < 2 &
TSS.enrichment > 1
)
# 记录过滤后的细胞数量
cells_after <- ncol(seurat_obj)
# 更新seurat_list
seurat_list[[sample_name]] <- seurat_obj
cat('样本', sample_name, '过滤完成: 过滤前', cells_before, '个细胞,过滤后', cells_after, '个细胞\n')
}正在对样本 S44R 进行质控过滤...n 样本 S44R 过滤完成: 过滤前 12068 个细胞,过滤后 12050 个细胞
计算样本间的共有 peaks
由于各样本独立进行 peak calling,不同样本中的 peaks 不一样。为了整合多样本,需要先统一 peaks 信息,创建所有样本的共有 peak 集合。
处理流程:
- 合并所有样本的 peaks
- 过滤 peak 长度(20bp-10kb)
- 为每个样本重新量化共有 peaks
注意事项: 如果前面读取数据用的第一种读取流程 rds 的方式,此部分不需要进行分析
注意事项: 如果前面读取数据用的第一种读取流程 rds 的方式,此部分不需要进行分析
注意事项: 如果前面读取数据用的第一种读取流程 rds 的方式,此部分不需要进行分析
# 提取每个样本的peaks信息
all_peaks <- lapply(seurat_list, function(x) {
DefaultAssay(x) <- "ATAC"
granges(x@assays$ATAC)
})
# 合并所有样本的peaks
gr_list <- GRangesList(all_peaks)
all_granges <- unlist(gr_list, use.names = FALSE)
combined.peaks <- reduce(x = all_granges)
# 过滤peaks长度(保留20bp-10kb的peaks)
peakwidths <- width(combined.peaks)
common_peaks <- combined.peaks[peakwidths < 10000 & peakwidths > 20]
cat('共有peaks数量:', length(common_peaks), '\n')
# 为每个样本量化共有peaks
seurat_list <- lapply(seurat_list, function(x) {
cat('正在为样本', x$Sample[1], '量化共有peaks...\n')
# 量化共有peaks的counts矩阵
combined_counts <- FeatureMatrix(
fragments = Fragments(x@assays$ATAC),
features = common_peaks,
cells = colnames(x)
)
# 创建新的ChromatinAssay
combined_peaks_assay <- CreateChromatinAssay(
counts = combined_counts,
fragments = Fragments(x@assays$ATAC),
annotation = Annotation(x@assays$ATAC)
)
# 添加到Seurat对象中
x[["combinedpeaks"]] <- combined_peaks_assay
DefaultAssay(x) <- "combinedpeaks"
x[["ATAC"]] <- NULL
return(x)
})正在为样本 S127 量化共有peaks...n
Extracting reads overlapping genomic regions
正在为样本 S44R 量化共有peaks...n
Extracting reads overlapping genomic regions
多样本合并
在多组学数据整合分析流程中,多样本合并是整合分析的重要前置步骤。
合并操作的目的:
- 将多个样本数据整合到同一个 Seurat 对象中
- 为后续的批次矫正和整合分析做准备
- 便于与批次矫正后的结果进行对比分析
重要说明:
- 此步骤仅进行简单的数据合并,尚未进行批次效应矫正
- 合并后的对象包含所有样本的原始数据
- 将合并的数据进行标准化、特征选择、PCA 降维和 UMAP 可视化等预处理步骤
suppressWarnings({
suppressMessages({
#合并scATAC-seq数据集
obj.combined <- merge(seurat_list[[1]], seurat_list[-1], merge.data = FALSE)
# 设置默认assay并进行标准化
DefaultAssay(obj.combined) <- "combinedpeaks"
obj.combined <- FindTopFeatures(obj.combined, min.cutoff = 10)
obj.combined <- RunTFIDF(obj.combined)
obj.combined <- RunSVD(obj.combined)
obj.combined <- RunUMAP(obj.combined, reduction = "lsi", dims = 2:30,reduction.name="atacumap")
})
})数据整合
现在我们将多个样本的 scATAC-seq 数据进行整合。scATAC-seq 数据整合主要有两种常用方法:
整合方法选择
CCA(Canonical Correlation Analysis)整合:
- 基于典型相关分析的整合方法
- 通过寻找样本间的共同变异模式进行整合
- 适用于样本间差异较大的情况
- Seurat 包的经典整合方法
Harmony 整合:
- 基于迭代聚类的快速整合方法
- 直接在降维空间中校正批次效应
- 计算效率高,适用于大规模数据
- 保留更多生物学变异信息
方法选择建议
- Harmony:同平台不同样本 scATAC-seq 数据;样本数量较多或数据量大,Harmony 方法更快。
- CCA:运行时间较久,通常批次效应严重的情况下推荐选 CCA,如跨平台的 scATAC-seq 数据
harmony 方法进行整合
注意:harmony 和 CCA 选择其中一种方法进行批次矫正
atac_integrate_harmony <- function(obj) {
library(harmony)
DefaultAssay(obj) <- "combinedpeaks"
obj<- RunHarmony(
object = obj,
group.by.vars = 'Sample',
reduction = 'lsi',
assay.use = 'combinepeaks',
reduction.save = "harmonylsi",
project.dim = FALSE
)
obj <- RunUMAP(obj,reduction = 'harmonylsi',reduction.name="atacharmonyumap", dims = 2:30)
#obj <- RunTSNE(obj, reduction = "harmonylsi",reduction.name="atacharmonytsne",dims = 2:50,check_duplicates = FALSE)
return(obj)
}
suppressWarnings({
suppressMessages({
integrated=atac_integrate_harmony(obj.combined)
integrated <- FindNeighbors(object = integrated, reduction = 'harmonylsi', graph.name = "atacneighbor", dims = 2:30)
integrated <- FindClusters(object = integrated, verbose = FALSE, graph.name = "atacneighbor",resolution = 0.5, algorithm = 3)
})
})
#可视化ATAC去批次效果
options(repr.plot.width=10, repr.plot.height=8)
DimPlot(integrated, reduction = "atacharmonyumap", group.by = "Sample")CCA 方法进行整合
注意:harmony 和 CCA 选择其中一种方法进行批次矫正
# 定义ATAC整合函数
options(future.globals.maxSize = 20 * 1024^3)
integrate_atac_cca <- function(object.list){
object.list <- lapply(object.list, function(x) {
DefaultAssay(x)="combinedpeaks"
x=RunTFIDF(x)
x=FindTopFeatures(x, min.cutoff = 5)
x=RunSVD(x)
return(x)
})
anchors <- FindIntegrationAnchors(
object.list = object.list,
anchor.features = rownames(obj.combined),
reduction = "rlsi",
dims = 2:30
)
integrated <- IntegrateEmbeddings(
anchorset = anchors,
reductions = obj.combined[["lsi"]],
new.reduction.name = "integrated_lsi",
dims.to.integrate = 1:30)
integrated<- RunUMAP(integrated, reduction = "integrated_lsi", dims = 2:30,reduction.name="atacintegratedumap")
#integrated<- RunTSNE(integrated, reduction = "integrated_lsi", dims = 2:30,reduction.name="atacintegratedtsne")
return(integrated)
}
# 执行ATAC整合
suppressWarnings({
suppressMessages({
integrated <- integrate_atac_cca(seurat_list)
integrated <- FindNeighbors(object = integrated, reduction = 'integrated_lsi', graph.name = "atacneighbor", dims = 2:30)
integrated <- FindClusters(object = integrated, verbose = FALSE, graph.name = "atacneighbor",resolution = 0.5, algorithm = 3)
})
})
#可视化ATAC去批次效果
options(repr.plot.width=10, repr.plot.height=8)
DimPlot(integrated, reduction = "atacintegratedumap", group.by = "Sample")开始处理各样本的LSI降维...n 寻找整合锚点...n 整合嵌入向量...
整合效果评估
比较整合前后的结果,评估整合效果。
评估指标:
- 样本混合程度:不同样本的细胞在 UMAP 图中的分布
- 批次效应去除:技术重复样本的聚集情况
- 生物学信号保留:已知细胞类型的分离度
suppressWarnings({
suppressMessages({
# 创建整合前的对照数据
obj.combined <- FindNeighbors(object = obj.combined,
reduction = 'lsi',
graph.name = "atacneighbor",
dims = 2:30)
# 聚类分析
obj.combined <- FindClusters(object = obj.combined,
verbose = FALSE,
graph.name = "atacneighbor",
cluster.name = "atac_clusters",
resolution = 0.5,
algorithm = 3)
})
})options(repr.plot.width=15, repr.plot.height=6)
#整合前样本分布
p1 <- DimPlot(obj.combined, split.by = "Sample" , cols = my36colors)+plot_annotation(title = "Before")
#整合后样本分布,根据前面整合方式,选择下面的reductionc参数
p2 <- DimPlot(integrated, split.by = "Sample" , cols = my36colors, reduction = "atacharmonyumap" ,group.by = "atacneighbor_res.0.5")+plot_annotation(title = "After")
#p2 <- DimPlot(integrated, split.by = "Sample" , cols = my36colors, reduction = "atacintegratedumap",group.by = "atacneighbor_res.0.5")+plot_annotation(title = "After")
p1
p2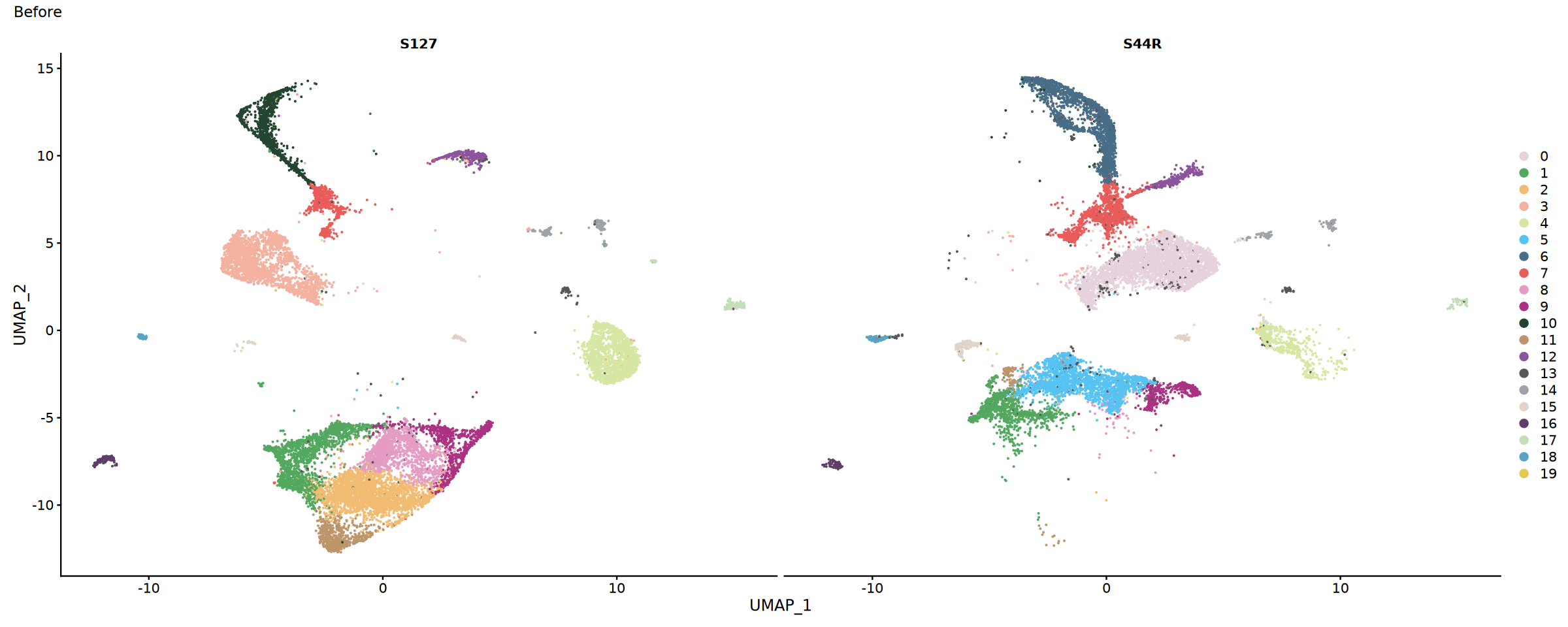
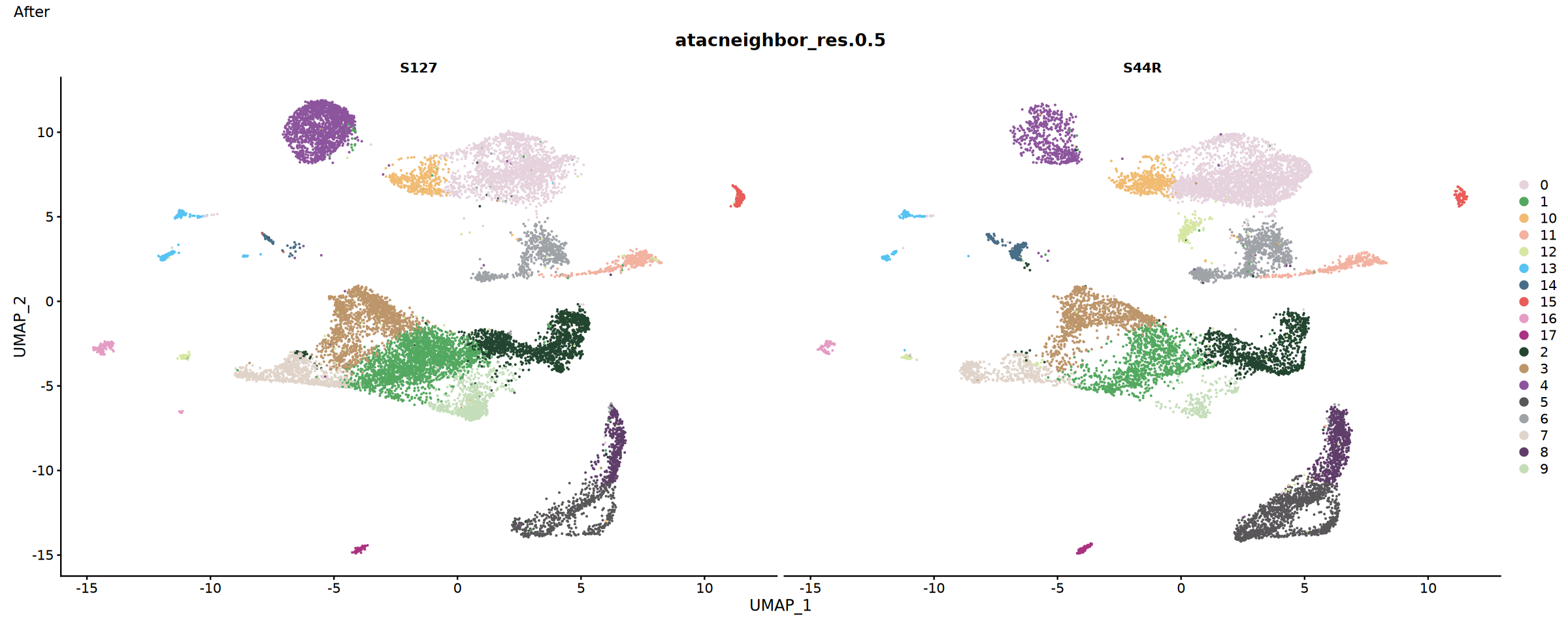
细胞注释
基于基因活性分数进行细胞类型注释,通过已知的 marker 基因识别不同的细胞类型。基因活力只能对 scATAC-seq 数据进行粗分类,具体 scATAC-seq 数据的注释策略有:
(1)基因活力进行粗分类;
(2)用同组织的已经注释过的 scRNA-seq 作为参考,将 scRNA-seq 细胞标签 transfer 到 scATAC-seq 上,完成细胞注释;
(3)用 Signac 包的 CoveragePlot,可视化 marker 基因 peaks 特异性开放情况,完成细胞注释。本教程只展示利用 marker 基因活力情况,对细胞进行注释。
基因活力分析
原理:统计与每个基因相关的 peaks 信号(如基因体 + 上下游一定范围的启动子区域),累积得到该基因在每个细胞的“活性分数”。
- 典型做法会取 TSS 上游 ~2kb、下游 ~1kb 的窗口(可按需要调整)
- 得到的
ACTIVITYassay 将用于与 RNA 的RNAassay 建立锚点
# 计算基因活性分数
gene.activities <- GeneActivity(integrated)
# 将基因活性矩阵添加为新的assay
integrated[['RNA']] <- CreateAssayObject(counts = gene.activities)
DefaultAssay(integrated)="RNA"
# 标准化基因活性数据
integrated <- NormalizeData(
object = integrated,
assay = 'RNA',
normalization.method = 'LogNormalize',
scale.factor = median(integrated$nCount_RNA)
)Extracting reads overlapping genomic regions
Extracting reads overlapping genomic regions
收集细胞类型典型 marker 基因
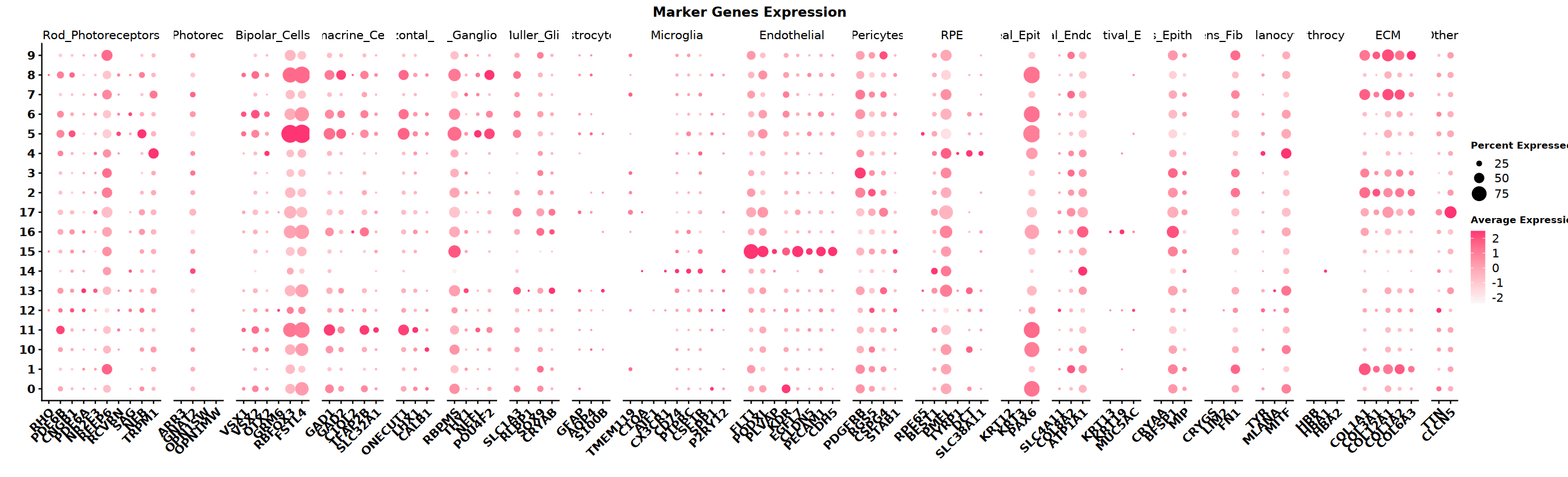
根据组织类型,收集不同细胞类型 marker 基因集,本示例数据是眼睛,下面是眼睛中细胞类型及其对应的 marker 基因,用气泡图可视化不同 cluster 高开放哪些细胞类型的 marker 基因
eye_marker_integrated <- list(
# ========== 光感受器细胞 ==========
"Rod_Photoreceptors" = c("RHO", "PDE6B", "CNGB1", "PDE6A", "NR2E3", "REEP6",
"RCVRN", "SAG", "NEB", "SLC24A3", "TRPM1"),
"Cone_Photoreceptors" = c("ARR3", "GNAT2", "OPN1SW", "OPN1MW", "TRPM3"),
# ========== 视网膜神经元 ==========
"Bipolar_Cells" = c("VSX1", "VSX2", "OTX2", "GRM6", "PRKCA",
"DLG2", "NRXN3", "RBFOX3", "FSTL4"),
"Amacrine_Cells" = c("GAD1", "GAD2", "C1QL2", "TFAP2B", "SLC32A1"),
"Horizontal_Cells" = c("ONECUT1", "LHX1", "CALB1", "NFIA"),
"Retinal_Ganglion_Cells" = c("RBPMS", "THY1", "NEFL", "POU4F2"),
# ========== 胶质细胞 ==========
"Muller_Glia" = c("SLC1A3", "RLBP1", "SOX9", "CRYAB"),
"Astrocytes" = c("GFAP", "AQP4", "S100B"),
"Microglia" = c("TMEM119", "C1QA", "AIF1", "CX3CR1", "CD74",
"PTPRC", "CSF1R", "CCL3L1", "SPP1", "P2RY12"),
# ========== 血管与支持细胞 ==========
"Endothelial" = c("FLT1", "PODXL", "PLVAP", "KDR", "EGFL7",
"CLDN5", "PECAM1", "CDH5"),
"Pericytes" = c("PDGFRB", "RGS5", "CSPG4", "STAB1"),
# ========== 上皮细胞 ==========
"RPE" = c("RPE65", "BEST1", "PMEL", "TYRP1", "DCT", "SLC38A11"),
"Corneal_Epithelial" = c("KRT12", "KRT3", "PAX6"),
"Corneal_Endothelial" = c("SLC4A11", "COL8A2", "ATP1A1"),
"Conjunctival_Epithelial" = c("KRT13", "KRT19", "MUC5AC"),
# ========== 晶状体细胞 ==========
"Lens_Epithelial" = c("CRYAA", "BFSP1", "MIP"),
"Lens_Fiber" = c("CRYGS", "LIM2", "FN1"),
# ========== 其他细胞 ==========
"Melanocytes" = c("TYR", "MLANA", "MITF"),
"Erythrocytes" = c("HBB", "HBA1", "HBA2"),
"ECM" = c("COL1A1", "COL3A1", "COL12A1", "COL1A2", "COL6A3"),
"Others" = c("TTN", "CLCN5", "DCC", "MIAT")
)# 设置图形大小
options(repr.plot.width=23, repr.plot.height=7)
# 绘制DotPlot
DotPlot(integrated,
group.by = "atacneighbor_res.0.5",
features = eye_marker_integrated,
cols = c("#f8f8f8","#ff3472"),
dot.min = 0.05,
dot.scale = 8)+ # 应用自定义配色
RotatedAxis() +
scale_x_discrete("") +
scale_y_discrete("") +
theme(
axis.text.x = element_text(size = 12, face = "bold",
angle = 45, hjust = 1, vjust = 1),
axis.text.y = element_text(size = 12, face = "bold"),
plot.title = element_text(size = 14, face = "bold", hjust = 0.5),
legend.title = element_text(size = 10, face = "bold")
) +
ggtitle("Marker Genes Expression") +
labs(color = "Expression\nLevel") # 修改图例标题"The following requested variables were not found: SLC24A3, TRPM3, PRKCA, DLG2, NRXN3, NFIA, CCL3L1, DCC, MIAT"
"Removed 530 rows containing missing values or values outside the scale range
(\`geom_point()\`)."
细胞类型标注
根据 marker 基因开放模式(即指基因活力情况),为每个聚类分配细胞类型标签。
# 基于聚类结果和marker基因表达定义细胞类型
# 注意:具体的聚类到细胞类型的映射需要根据marker基因表达结果调整
integrated$celltype <- recode(integrated$atacneighbor_res.0.5,
"0" = "Photoreceptors",
"1" = "ECM",
"2" = "ECM",
"3" = "ECM",
"4" = "Rod_photoreceptors",
"5" = "Bipolar_Cells",
"6" = "Amacrine_Horizontal",
"7" = "ECM",
"8" = "Bipolar_Cells",
"9" = "ECM",
"10" = "Photoreceptors",
"11" = "Amacrine_Horizontal",
"12" = "Photoreceptors",
"13" = "Muller_Glia",
"14" = "Microglia",
"15" = "Endothelial",
"16" = "Muller_Glia",
"17" = "ECM"
)# 基础UMAP图
p1 <- DimPlot(integrated,
cols = my36colors,
group.by = "celltype",
label = TRUE) +
ggtitle("Cell Type Annotation")
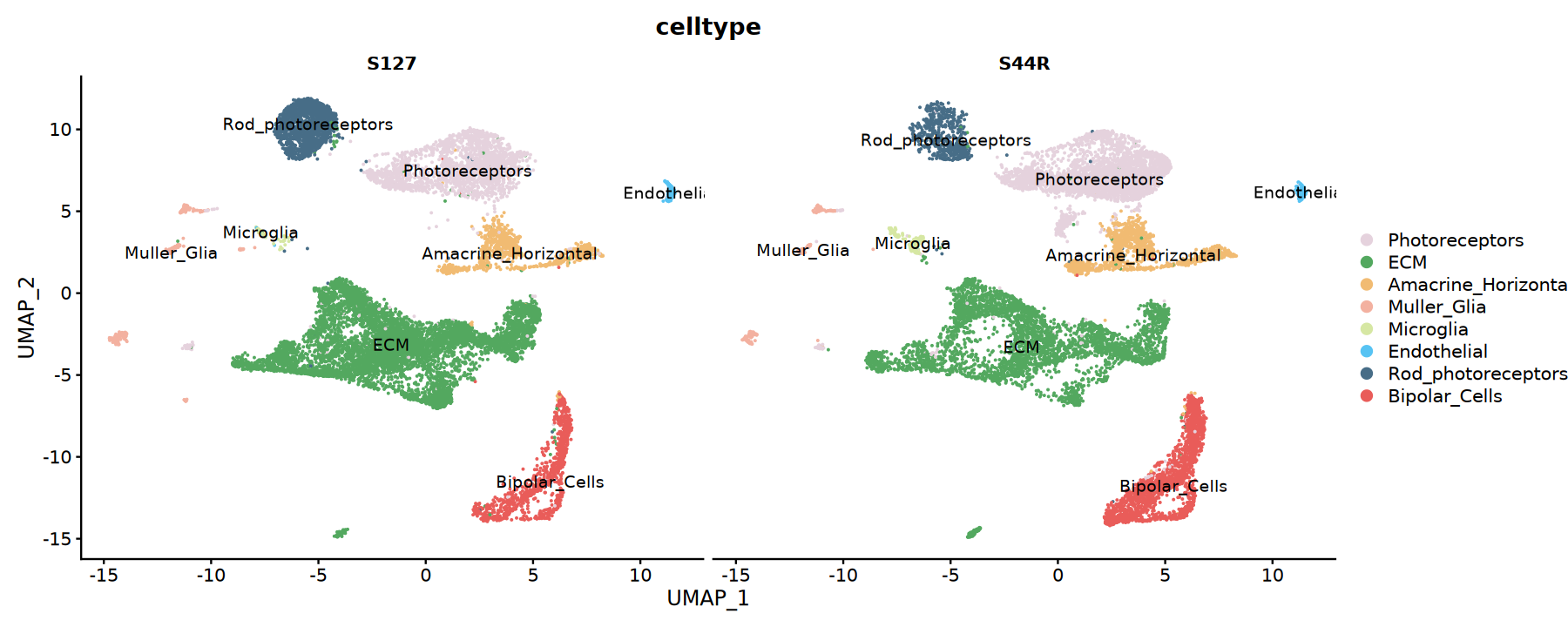
# 分样本UMAP图
p2 <- DimPlot(integrated,
cols = my36colors,
split.by = "Sample",
group.by = "celltype",
label = TRUE)
# 保存PDF(高质量矢量图)
ggsave('./celltype_annotation_umap.pdf', p1, width = 8, height = 6)
ggsave('./celltype_by_sample_umap.pdf', p2, width = 16, height = 6)
# 展示图形
# 设置绘图尺寸
options(repr.plot.width=9, repr.plot.height=6)
print(p1)
# 设置绘图尺寸
options(repr.plot.width=15, repr.plot.height=6)
print(p2)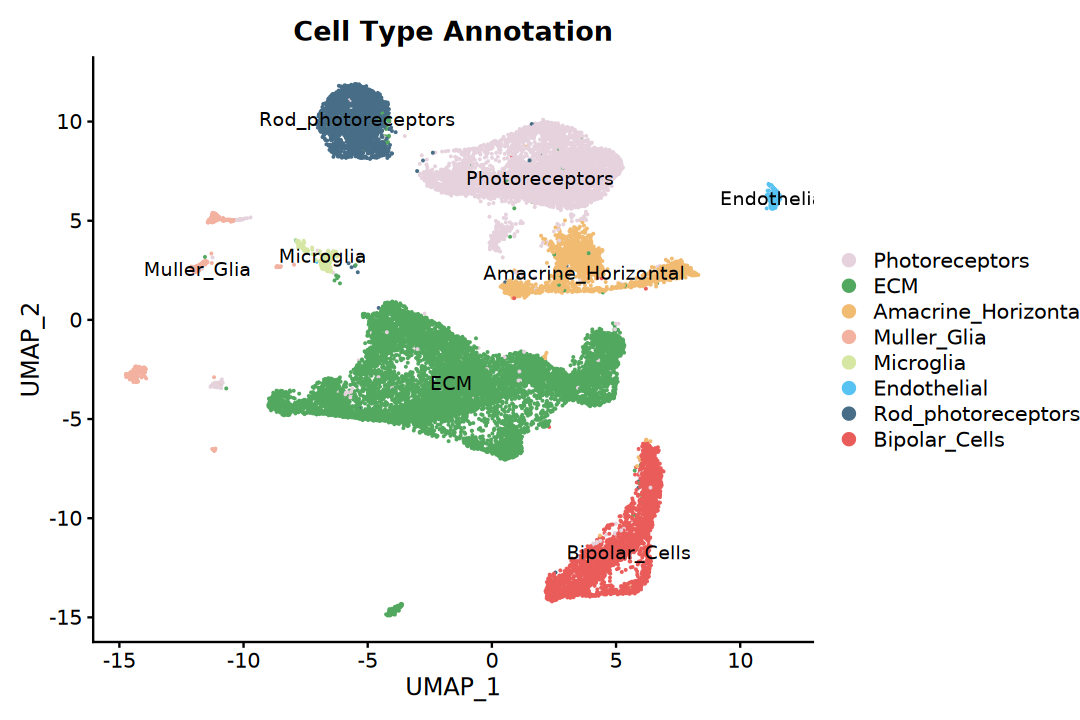
结果保存
保存整合后的对象与关键图表,建议同时保存中间对象以便复现与后续复查。
saveRDS(integrated, file = "./integrated.rds")总结
本教程演示了 scATAC-seq 多样本整合分析的完整流程:
关键技术点
- TF-IDF 标准化:适用于稀疏的 scATAC-seq 数据
- LSI 降维:潜在语义索引,比 PCA 更适合 scATAC-seq 数据
- peaks 合并:统一不同样本的 peak 集合是整合的关键步骤
- 基因活性分数:将 peaks 信号转换为基因水平的活性分数
注意事项
- 质控阈值:需要根据具体数据特征调整过滤参数
- 整合参数:LSI 维度选择和整合参数需要优化
- 细胞注释:需要结合生物学知识和 marker 基因表达进行手动注释
- 计算资源:scATAC-seq 数据量大,需要足够的内存和计算资源
后续分析建议
- 差异可及性区域(DAR)分析
- 转录因子足迹分析
- 基因调控网络推断
- 与 scRNA-seq 数据的多组学整合分析
- 细胞轨迹和伪时间分析
sessionInfo()Platform: x86_64-conda-linux-gnu (64-bit)
Running under: Debian GNU/Linux 12 (bookworm)
Matrix products: default
BLAS/LAPACK: /jp_envs/envs/common/lib/libopenblasp-r0.3.29.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: Asia/Shanghai
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] future_1.40.0 patchwork_1.3.0
[3] ggplot2_3.5.2 dplyr_1.1.4
[5] biovizBase_1.50.0 BSgenome.Hsapiens.UCSC.hg38_1.4.5
[7] BSgenome_1.70.1 rtracklayer_1.62.0
[9] BiocIO_1.12.0 Biostrings_2.70.1
[11] XVector_0.42.0 EnsDb.Hsapiens.v86_2.99.0
[13] ensembldb_2.26.0 AnnotationFilter_1.26.0
[15] GenomicFeatures_1.54.1 AnnotationDbi_1.64.1
[17] Biobase_2.62.0 GenomicRanges_1.54.1
[19] GenomeInfoDb_1.38.1 IRanges_2.36.0
[21] S4Vectors_0.40.2 BiocGenerics_0.48.1
[23] Signac_1.10.0 SeuratObject_4.1.4
[25] Seurat_4.4.0 repr_1.1.7
loaded via a namespace (and not attached):
[1] ProtGenerics_1.34.0 matrixStats_1.5.0
[3] spatstat.sparse_3.1-0 bitops_1.0-9
[5] httr_1.4.7 RColorBrewer_1.1-3
[7] tools_4.3.3 sctransform_0.4.1
[9] backports_1.5.0 R6_2.6.1
[11] lazyeval_0.2.2 uwot_0.2.3
[13] withr_3.0.2 sp_2.2-0
[15] prettyunits_1.2.0 gridExtra_2.3
[17] progressr_0.15.1 cli_3.6.4
[19] Cairo_1.6-2 spatstat.explore_3.4-2
[21] labeling_0.4.3 spatstat.data_3.1-6
[23] ggridges_0.5.6 pbapply_1.7-2
[25] Rsamtools_2.18.0 pbdZMQ_0.3-13
[27] foreign_0.8-87 R.utils_2.13.0
[29] dichromat_2.0-0.1 parallelly_1.43.0
[31] rstudioapi_0.15.0 RSQLite_2.3.9
[33] generics_0.1.3 ica_1.0-3
[35] spatstat.random_3.3-3 Matrix_1.6-5
[37] ggbeeswarm_0.7.2 abind_1.4-5
[39] R.methodsS3_1.8.2 lifecycle_1.0.4
[41] yaml_2.3.10 SummarizedExperiment_1.32.0
[43] SparseArray_1.2.2 BiocFileCache_2.10.1
[45] Rtsne_0.17 grid_4.3.3
[47] blob_1.2.4 promises_1.3.2
[49] crayon_1.5.3 miniUI_0.1.1.1
[51] lattice_0.22-7 cowplot_1.1.3
[53] KEGGREST_1.42.0 pillar_1.10.2
[55] knitr_1.49 rjson_0.2.23
[57] future.apply_1.11.3 codetools_0.2-20
[59] fastmatch_1.1-6 leiden_0.4.3.1
[61] glue_1.8.0 spatstat.univar_3.1-2
[63] data.table_1.17.0 vctrs_0.6.5
[65] png_0.1-8 gtable_0.3.6
[67] cachem_1.1.0 xfun_0.50
[69] S4Arrays_1.2.0 mime_0.13
[71] survival_3.8-3 RcppRoll_0.3.1
[73] fitdistrplus_1.2-2 ROCR_1.0-11
[75] nlme_3.1-168 bit64_4.5.2
[77] progress_1.2.3 filelock_1.0.3
[79] RcppAnnoy_0.0.22 irlba_2.3.5.1
[81] vipor_0.4.7 KernSmooth_2.23-26
[83] rpart_4.1.23 colorspace_2.1-1
[85] DBI_1.2.3 Hmisc_5.2-1
[87] nnet_7.3-19 ggrastr_1.0.2
[89] tidyselect_1.2.1 bit_4.5.0.1
[91] compiler_4.3.3 curl_6.0.1
[93] htmlTable_2.4.3 xml2_1.3.6
[95] DelayedArray_0.28.0 plotly_4.10.4
[97] checkmate_2.3.2 scales_1.3.0
[99] lmtest_0.9-40 rappdirs_0.3.3
[101] stringr_1.5.1 digest_0.6.37
[103] goftest_1.2-3 spatstat.utils_3.1-3
[105] rmarkdown_2.29 htmltools_0.5.8.1
[107] pkgconfig_2.0.3 base64enc_0.1-3
[109] MatrixGenerics_1.14.0 dbplyr_2.5.0
[111] fastmap_1.2.0 rlang_1.1.5
[113] htmlwidgets_1.6.4 shiny_1.10.0
[115] farver_2.1.2 zoo_1.8-14
[117] jsonlite_2.0.0 BiocParallel_1.36.0
[119] R.oo_1.27.0 VariantAnnotation_1.48.1
[121] RCurl_1.98-1.16 magrittr_2.0.3
[123] Formula_1.2-5 GenomeInfoDbData_1.2.11
[125] IRkernel_1.3.2 munsell_0.5.1
[127] Rcpp_1.0.14 reticulate_1.42.0
[129] stringi_1.8.7 zlibbioc_1.48.0
[131] MASS_7.3-60.0.1 plyr_1.8.9
[133] parallel_4.3.3 listenv_0.9.1
[135] ggrepel_0.9.6 deldir_2.0-4
[137] IRdisplay_1.1 splines_4.3.3
[139] tensor_1.5 hms_1.1.3
[141] igraph_2.0.3 uuid_1.2-1
[143] spatstat.geom_3.3-6 reshape2_1.4.4
[145] biomaRt_2.58.0 XML_3.99-0.17
[147] evaluate_1.0.3 httpuv_1.6.15
[149] RANN_2.6.2 tidyr_1.3.1
[151] purrr_1.0.4 polyclip_1.10-7
[153] scattermore_1.2 xtable_1.8-4
[155] restfulr_0.0.15 later_1.4.2
[157] viridisLite_0.4.2 tibble_3.2.1
[159] memoise_2.0.1 beeswarm_0.4.0
[161] GenomicAlignments_1.38.0 cluster_2.1.8.1
[163] globals_0.16.3