scFAST-seq 突变分析:数据合并、UMAP 展示与整合
时长: 15 分钟
字数: 3.2k 字
更新: 2026-02-28
阅读: 0 次
右上角选择 R 环境
R
library(Seurat)
library(dplyr)
library(Matrix)
library(stringr)
library(ggplot2)
options(repr.plot.width = 12, repr.plot.height = 6)output
The legacy packages maptools, rgdal, and rgeos, underpinning this package
will retire shortly. Please refer to R-spatial evolution reports on
https://r-spatial.org/r/2023/05/15/evolution4.html for details.
This package is now running under evolution status 0
rgeos version: 0.6-3, (SVN revision 696)
GEOS runtime version: 3.11.2-CAPI-1.17.2
Please note that rgeos will be retired during October 2023,
plan transition to sf or terra functions using GEOS at your earliest convenience.
See https://r-spatial.org/r/2023/05/15/evolution4.html for details.
GEOS using OverlayNG
Linking to sp version: 1.6-0
Polygon checking: TRUE
Attaching SeuratObject
Attaching sp
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
will retire shortly. Please refer to R-spatial evolution reports on
https://r-spatial.org/r/2023/05/15/evolution4.html for details.
This package is now running under evolution status 0
rgeos version: 0.6-3, (SVN revision 696)
GEOS runtime version: 3.11.2-CAPI-1.17.2
Please note that rgeos will be retired during October 2023,
plan transition to sf or terra functions using GEOS at your earliest convenience.
See https://r-spatial.org/r/2023/05/15/evolution4.html for details.
GEOS using OverlayNG
Linking to sp version: 1.6-0
Polygon checking: TRUE
Attaching SeuratObject
Attaching sp
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
将突变数据合并到单样本 rds 里
输入数据
- 单样本 rds(可以选择对应分析流程的 rds)
- 该样本的两个突变矩阵(all/alt,可联系客户经理申请释放,仅限于全序列数据)
矩阵文件可以在左上角的 upload 处点击上传
需要修改的内容
修改下方的 rds 路径,相对目录为../data/,绝对目录为/home/mambauser/data/
修改下方的矩阵文件名
R
#load rds and matrix
obj = readRDS("data/AY1732591902625/input.rds") # AY1732591902625为流程ID
# AY1732591902625为流程ID
meta = read.table("data/AY1732591902625/meta.tsv", header = T, sep = "\t", check.names = F)
rownames(meta) = meta$barcode
obj = AddMetaData(object = obj,metadata = meta)
snv_cover_mat = read.delim("PBMC.snp_indel.all_UMI.matrix", header = T, row.names = 1)
snv_mut_mat = read.delim("PBMC.snp_indel.alt_UMI.matrix", header = T, row.names = 1)查看矩阵
R
snv_cover_mat[1:3, 1:3]
snv_mut_mat[1:3, 1:3]| AAGTTCGTACTGGTTCT | CTGCAGGTACGGAGTAG | TAACGACCGACTGCGCA | |
|---|---|---|---|
| <int> | <int> | <int> | |
| SDF4:chr1-1223263:T>G | 0 | 0 | 0 |
| SLC35E2B:chr1-1668373:C>T | 0 | 0 | 0 |
| CDK11A:chr1-1709071:C>T | 0 | 0 | 0 |
| AAGTTCGTACTGGTTCT | CTGCAGGTACGGAGTAG | TAACGACCGACTGCGCA | |
|---|---|---|---|
| <int> | <int> | <int> | |
| SDF4:chr1-1223263:T>G | 0 | 0 | 0 |
| SLC35E2B:chr1-1668373:C>T | 0 | 0 | 0 |
| CDK11A:chr1-1709071:C>T | 0 | 0 | 0 |
R
# Function:process cover/mut matrix
## object : Seurat object
## mat : matrix or dgCMatrix or data.frame
## assay_name: specified new assay name for matrix
generate_mat = function(object, mat, assay_name) {
#make sure consistent of barcodes
diff_barcode = setdiff(colnames(object), colnames(mat))
if (length(diff_barcode) == ncol(object)) {
stop("no common barcodes between matrix and seurat object")
}
if (length(diff_barcode) != 0) {
diff_matrix = matrix(0,
nrow = nrow(mat),
ncol = length(diff_barcode),
dimnames = list(rownames(mat), diff_barcode))
mat = cbind(mat, diff_matrix)
}
mat = as(as.matrix(mat), 'dgCMatrix')
#reorder barcode according rds
mat = mat[, colnames(object)]
#add new assay into rds
object[[assay_name]] = CreateAssayObject(mat)
return(object)
}运行该命令,分别将突变矩阵和覆盖矩阵加入到 obj 中
R
#cover matrix
obj = generate_mat(object = obj, mat = snv_cover_mat, assay_name = "SNV_all")
#mutation matrix
obj = generate_mat(object = obj, mat = snv_mut_mat, assay_name = "SNV")output
Warning message:
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
obj 有三个 assay,添加成功
R
#result
Assays(obj)- 'RNA'
- 'SNV_all'
- 'SNV'
R
#check value
obj@assays$SNV[1:3,1:3]output
3 x 3 sparse Matrix of class "dgCMatrix"
AAGTTCGTACTGGTTCT CTGCAGGTACGGAGTAG CCTCTAGATGTAATTCC
SDF4:chr1-1223263:T>G . . .
SLC35E2B:chr1-1668373:C>T . . .
CDK11A:chr1-1709071:C>T . . .
AAGTTCGTACTGGTTCT CTGCAGGTACGGAGTAG CCTCTAGATGTAATTCC
SDF4:chr1-1223263:T>G . . .
SLC35E2B:chr1-1668373:C>T . . .
CDK11A:chr1-1709071:C>T . . .
保存 rds
R
saveRDS(obj, file = "add_snv.rds")展示突变的发生情况
展示单个突变在细胞群上的发生情况
指定 assay 为 SNV,即指定突变矩阵,展示发生该突变的细胞
例如指定突变:SLC35E2B:chr1-1668373:C>T
R
DefaultAssay(obj) = "SNV"
FeaturePlot(obj, features = "SLC35E2B:chr1-1668373:C>T",ncol = 2) +
DimPlot(obj, group.by = "resolution.0.8", label = T)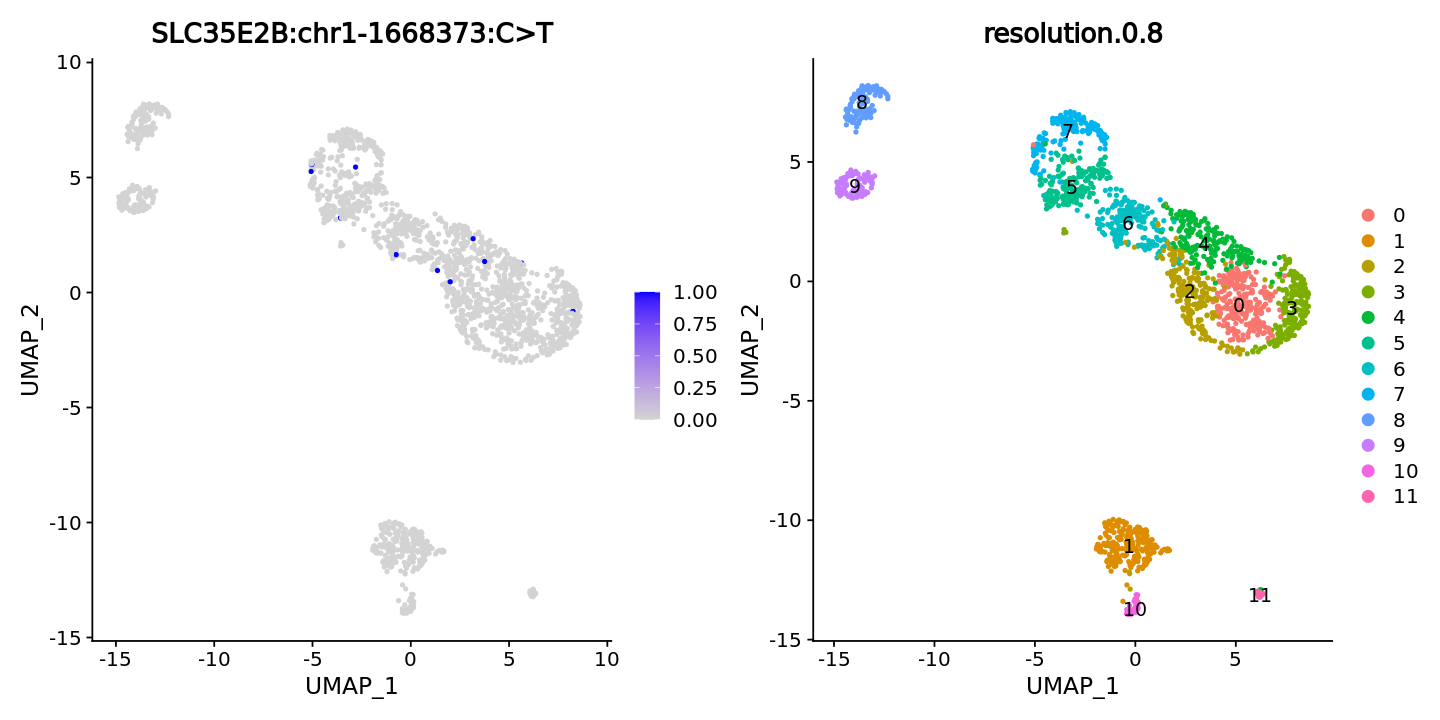
保存图片
图片文件名为 SLC35E2B_C_to_T_mut.png,保存在当前目录下,可在左侧下载图片
R
p = FeaturePlot(obj, features = "SLC35E2B:chr1-1668373:C>T",ncol = 2) +
DimPlot(obj, group.by = "resolution.0.8", label = T)
ggsave(p, file = "SLC35E2B_C_to_T_mut.png", width = 12, height = 6)展示多个突变在细胞群上的发生情况
指定 assay 为 SNV,即指定突变矩阵,展示发生该突变的细胞
例如指定前 5 个突变
R
DefaultAssay(obj) = "SNV"
head5_mut = head(rownames(obj), 5)
head5_mut- 'SDF4:chr1-1223263:T>G'
- 'SLC35E2B:chr1-1668373:C>T'
- 'CDK11A:chr1-1709071:C>T'
- 'RPL22:chr1-6197724:C>T'
- 'DNAJC11:chr1-6667742:TTC>-'
批量保存图片
R
for ( i in head5_mut) {
p = FeaturePlot(obj, features = i, ncol = 2)
filename = stringr::str_replace_all(i, "[:>]", "_")
ggsave(p, file = paste0(filename, ".png"), width = 6, height = 6) #保存在当前目录下
}展示覆盖到该位点的细胞群
指定 assay 为 SNV_all,即指定覆盖矩阵,展示覆盖到该突变所在位点的细胞
R
DefaultAssay(obj) = "SNV_all"
FeaturePlot(obj, features = "SLC35E2B:chr1-1668373:C>T",ncol = 2) +
DimPlot(obj, group.by = "resolution.0.8", label = T)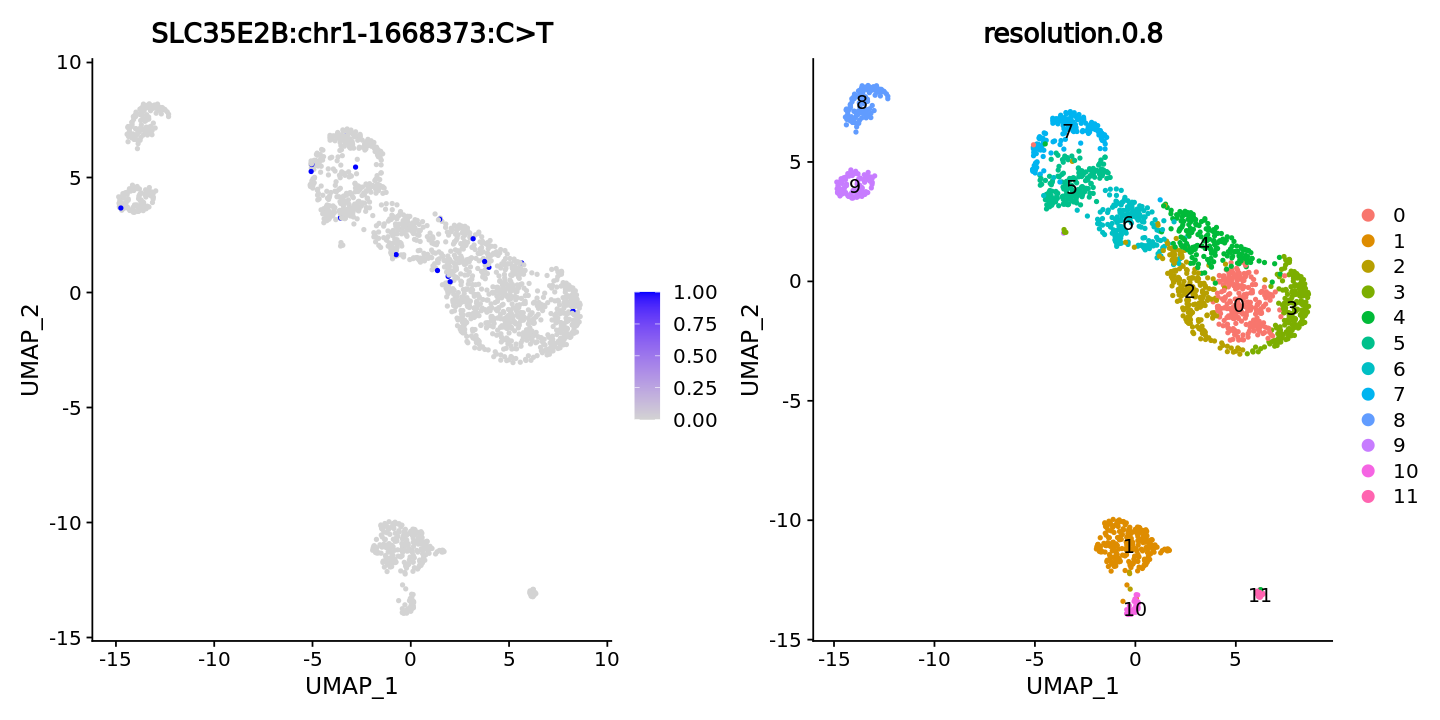
展示该突变所在基因的表达情况
指定 assay 为 RNA,即指定表达数据,展示该突变所在基因的表达情况
R
DefaultAssay(obj) = "RNA"
FeaturePlot(obj, features = "SLC35E2B",ncol = 2) +
DimPlot(obj, group.by = "resolution.0.8", label = T)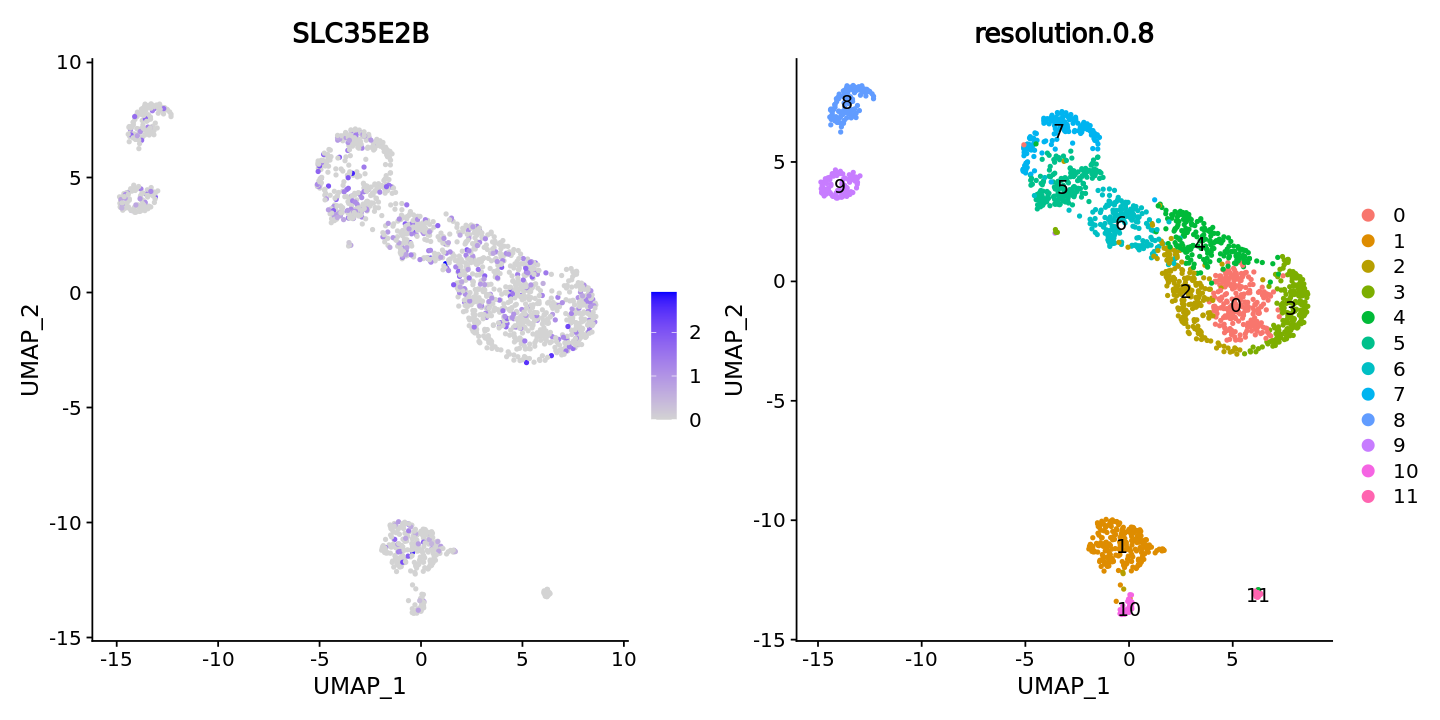
将是否发生突变添加为新的标签
将细胞分类为两类:发生该突变/未发生该突变,并作为新的标签进行展示;
例如指定突变为"SLC35E2B:chr1-1668373:C>T"
R
interest_mut = "SLC35E2B:chr1-1668373:C>T"
DefaultAssay(obj) = "SNV"
mut_label = FetchData(obj, interest_mut)
mut_label = ifelse(mut_label == 0, "negative", "positive")
table(mut_label)output
mut_label
negative positive
1909 12
negative positive
1909 12
添加标签
R
obj = AddMetaData(obj, metadata = mut_label, col.name = "SLC35E2B_C_to_T")展示
R
DefaultAssay(obj) = "RNA"
FeaturePlot(obj, features = "SLC35E2B",ncol = 2) +
DimPlot(obj, group.by = "SLC35E2B_C_to_T", cols = c("grey","red"))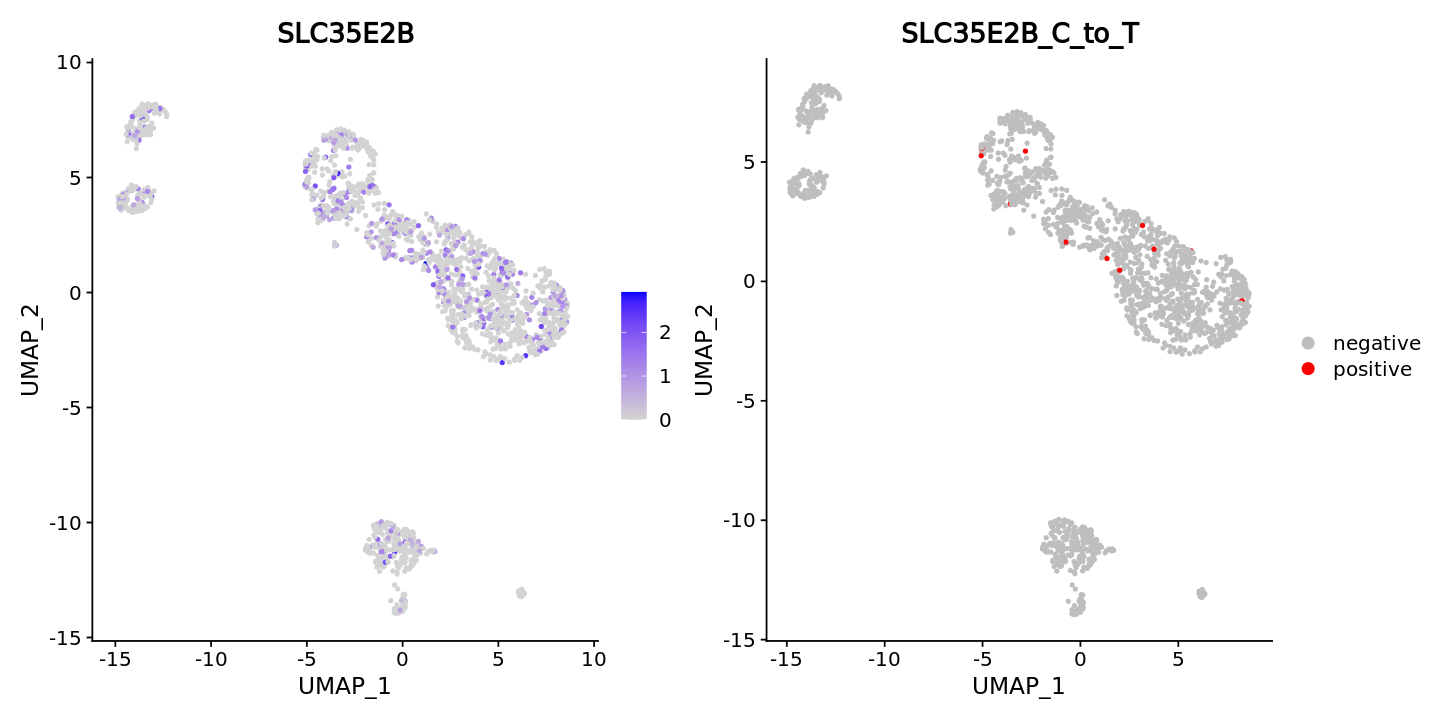
导出表格
R
df = data.frame(barcode = colnames(obj),
SLC35E2B_C_to_T = mut_label)
head(df)
write.csv(df, file="SLC35E2B_C_to_T_mut_meta.csv", quote=F, row.names = F)| barcode | SLC35E2B.chr1.1668373.C.T | |
|---|---|---|
| <chr> | <chr> | |
| AAGTTCGTACTGGTTCT | AAGTTCGTACTGGTTCT | negative |
| CTGCAGGTACGGAGTAG | CTGCAGGTACGGAGTAG | negative |
| CCTCTAGATGTAATTCC | CCTCTAGATGTAATTCC | negative |
| TAACGACCGACTGCGCA | TAACGACCGACTGCGCA | negative |
| ATCAGGTGCTTTCAGAC | ATCAGGTGCTTTCAGAC | negative |
| GACCCTTTACGTGTTCC | GACCCTTTACGTGTTCC | negative |
上传表格到云平台
表格保存到当前路径下,在左侧点击下载,进入云平台
云平台-选择分析流程-辅助信息-标签管理-新增标签-上传合并 meta-点击上传
全序列突变数据的多样本整合
将多个样本的突变矩阵与整合后 rds 进行合并,从而可以在样本间进行突变的相关分析。
输入数据
- 整合后 rds。(可以选择对应分析流程)
- 各个样本的突变发生矩阵,覆盖矩阵(all/alt,可联系客户经理申请释放,仅限于全序列数据)
例如:整合 rds 中 SAMple 列为"PBMC", 突变矩阵文件名为 "PBMC.snp_indel.all_UMI.matrix", "PBMC.snp_indel.alt_UMI.matrix"
矩阵文件可以在左上角的 upload 处点击上传
需要修改的内容
修改下方的 rds 路径,相对目录为../data/,绝对目录为/home/mambauser/data/
修改下方的矩阵文件名
R
##read integrated rds
integrate_obj = readRDS("integrated_seurat.rds") #或 integrate_obj = readRDS("data/流程ID/input.rds")
unique(integrate_obj$Sample)
#snv_cover_mat&snv_mut_mat的矩阵文件需放在当前工作目录下,您可以通过setwd()来更改工作目录
snv_cover_mat = c("PBMC.snp_indel.all_UMI.matrix", "cellline.snp_indel.all_UMI.matrix")
snv_mut_mat = c("PBMC.snp_indel.alt_UMI.matrix", "cellline.snp_indel.alt_UMI.matrix")- 'PBMC'
- 'cellline'
R
# Function:process cover/mut matrix
## object : Seurat object
## mat : matrix or dgCMatrix or data.frame
## assay_name: specified new assay name for matrix
generate_mat = function(object, mat, assay_name) {
#make sure consistent of barcodes
diff_barcode = setdiff(colnames(object), colnames(mat))
if (length(diff_barcode) == ncol(object)) {
stop("no common barcodes between matrix and seurat object")
}
if (length(diff_barcode) != 0) {
diff_matrix = matrix(0,
nrow = nrow(mat),
ncol = length(diff_barcode),
dimnames = list(rownames(mat), diff_barcode))
mat = cbind(mat, diff_matrix)
}
mat = as(as.matrix(mat), 'dgCMatrix')
#reorder barcode according rds
mat = mat[, colnames(object)]
#add new assay into rds
object[[assay_name]] = CreateAssayObject(mat)
return(object)
}
# Function:process cover/mut matrix for integrated rds
## object: Seurat object
## snv_cover_mat: vector, cover matrix for each sample
## snv_mut_mat:vector, mut matrix for each sample
## meta_name: column name in meta.data, contains samples' name, same as marix filename's prefix
## cover_assay_name : new assay name for cover matrix
## mut_assay_name : new assay name for mut matrix
generate_mat_integrated = function(object,
snv_cover_mat,
snv_mut_mat,
meta_name = "Sample",
cover_assay_name = "SNV_all",
mut_assay_name = "SNV") {
#get barcode suffix for each sample
suffix = as.data.frame(object@meta.data) %>%
select(sym(meta_name)) %>%
unique()
suffix$barcode = rownames(suffix)
suffix$suffix = stringr::str_replace_all(suffix$barcode,
"[A-Z]{17}", "")
#check sample name
cover_sample = stringr::str_replace_all(snv_cover_mat,
".snp_indel.all_UMI.matrix","")
mut_sample = stringr::str_replace_all(snv_mut_mat,
".snp_indel.alt_UMI.matrix","")
if(! identical(cover_sample, mut_sample)) {
stop("filenames are not same for snv_cover_mat and snv_mut_mat")
}
if(! all(suffix[[meta_name]] %in% cover_sample)) {
stop("some samples do not have corresponding matrix files")
}
#get all matrix, add suffix
cover_mat_list = lapply(1:nrow(suffix), function(e) {
mat = read.delim(paste0(suffix[[meta_name]][e], ".snp_indel.all_UMI.matrix"),
header = T, row.names = 1)
colnames(mat) = paste0(colnames(mat), suffix[["suffix"]][e])
as.matrix(mat)
})
mut_mat_list = lapply(1:nrow(suffix), function(e) {
mat = read.delim(paste0(suffix[[meta_name]][e], ".snp_indel.alt_UMI.matrix"),
header = T, row.names = 1)
colnames(mat) = paste0(colnames(mat), suffix[["suffix"]][e])
as.matrix(mat)
})
##define two matrix
all_muts = unique(unlist(lapply(cover_mat_list, rownames)))
all_barcodes = unlist(lapply(cover_mat_list, colnames))
all_cover_mat = Matrix::Matrix(0,
nrow = length(all_muts),
ncol = length(all_barcodes),
dimnames = list(all_muts, all_barcodes))
all_mut_mat = Matrix::Matrix(0,
nrow = length(all_muts),
ncol = length(all_barcodes),
dimnames = list(all_muts, all_barcodes))
#fill in value
for (i in seq.int(cover_mat_list)) {
mat = cover_mat_list[[i]]
all_cover_mat[rownames(mat), colnames(mat)] = mat
mat = mut_mat_list[[i]]
all_mut_mat[rownames(mat), colnames(mat)] = mat
}
#add new assay, function is from top-line in this file
object = generate_mat(object,
mat = all_cover_mat,
assay_name = cover_assay_name)
object = generate_mat(object,
mat = all_mut_mat,
assay_name = mut_assay_name)
}运行命令,合并数据
R
integrate_obj = generate_mat_integrated(integrate_obj,
snv_cover_mat,
snv_mut_mat,
meta_name = "Sample")output
Warning message:
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
新对象有三个 assay,添加成功
R
Assays(integrate_obj)- 'RNA'
- 'SNV_all'
- 'SNV'
保存数据
R
saveRDS(integrate_obj, file = "integrate_add_snv.rds")也可以先合并数据,再做整合
R
#PBMC data
obj1 = readRDS("PBMC_seurat.rds")
snv_cover_mat1 = read.delim("PBMC.snp_indel.all_UMI.matrix", header = T, row.names = 1)
snv_mut_mat1 = read.delim("PBMC.snp_indel.alt_UMI.matrix", header = T, row.names = 1)
#cover matrix
obj1 = generate_mat(object = obj1, mat = snv_cover_mat1, assay_name = "SNV_all")
#mutation matrix
obj1 = generate_mat(object = obj1, mat = snv_mut_mat1, assay_name = "SNV")output
Warning message:
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
R
#cellline data
obj2 = readRDS("cellline_seurat.rds")
snv_cover_mat2 = read.delim("cellline.snp_indel.all_UMI.matrix", header = T, row.names = 1)
snv_mut_mat2 = read.delim("cellline.snp_indel.alt_UMI.matrix", header = T, row.names = 1)
#cover matrix
obj2 = generate_mat(object = obj2, mat = snv_cover_mat2, assay_name = "SNV_all")
#mutation matrix
obj2 = generate_mat(object = obj2, mat = snv_mut_mat2, assay_name = "SNV")output
Warning message:
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
“Keys should be one or more alphanumeric characters followed by an underscore, setting key from snv_all_ to snvall_”
R
integrate_obj = merge(obj1, obj2)output
Warning message in CheckDuplicateCellNames(object.list = objects):
“Some cell names are duplicated across objects provided. Renaming to enforce unique cell names.”
“Some cell names are duplicated across objects provided. Renaming to enforce unique cell names.”
新对象有三个 assay,添加成功
R
Assays(integrate_obj)- 'RNA'
- 'SNV_all'
- 'SNV'
保存数据
R
saveRDS(integrate_obj, file = "integrate_add_snv.rds")