细胞注释
完成所构建项目的“基础分析”后,可进入“细胞注释”模块。该模块展示细胞注释前后的降维图、cluster 差异基因列表及 top 基因的可视化结果,并可分别对多组聚类结果进行自动注释(SingleR 算法)和手动注释。
理论基础
什么是细胞注释
细胞注释 (Cell Annotation) 是指根据单细胞基因表达谱,为每个细胞或细胞群赋予其生物学身份(即细胞类型)的过程。这一过程依赖于已知的标记基因 (Marker Genes) ——那些在特定细胞类型中特异性高表达的基因。
细胞注释的核心原则
NOTE
- 特异性 (Specificity):理想的标记基因应仅在目标细胞类型中高表达,在其他类型中不表达或低表达。
- 广度 (Coverage):标记基因应在目标细胞类型的大部分细胞中稳定表达。
- 分层性 (Hierarchy):细胞身份存在层级关系,如免疫细胞(大群)可进一步分为 T 细胞、B 细胞、巨噬细胞等亚群。注释时应遵循从宏观到微观的原则。
- 多证据支持 (Multiple Lines of Evidence):不能仅依赖单个标记基因,应结合多个基因的表达模式、功能富集分析以及参考数据库进行综合判断。
大群注释与亚群注释
- 大群注释 (Major-lineage Annotation):识别主要的细胞谱系,如免疫细胞、上皮细胞、基质细胞等。此阶段的目标是建立整个数据集的细胞组成概览。
- 亚群注释 (Sub-cluster Annotation):在已确定的大群内部,进一步鉴定更精细的细胞亚型。例如,在 T 细胞群中区分 CD4+ T 细胞、CD8+ T 细胞、调节性 T 细胞等。亚群注释是深入研究细胞异质性和功能的关键。
界面说明
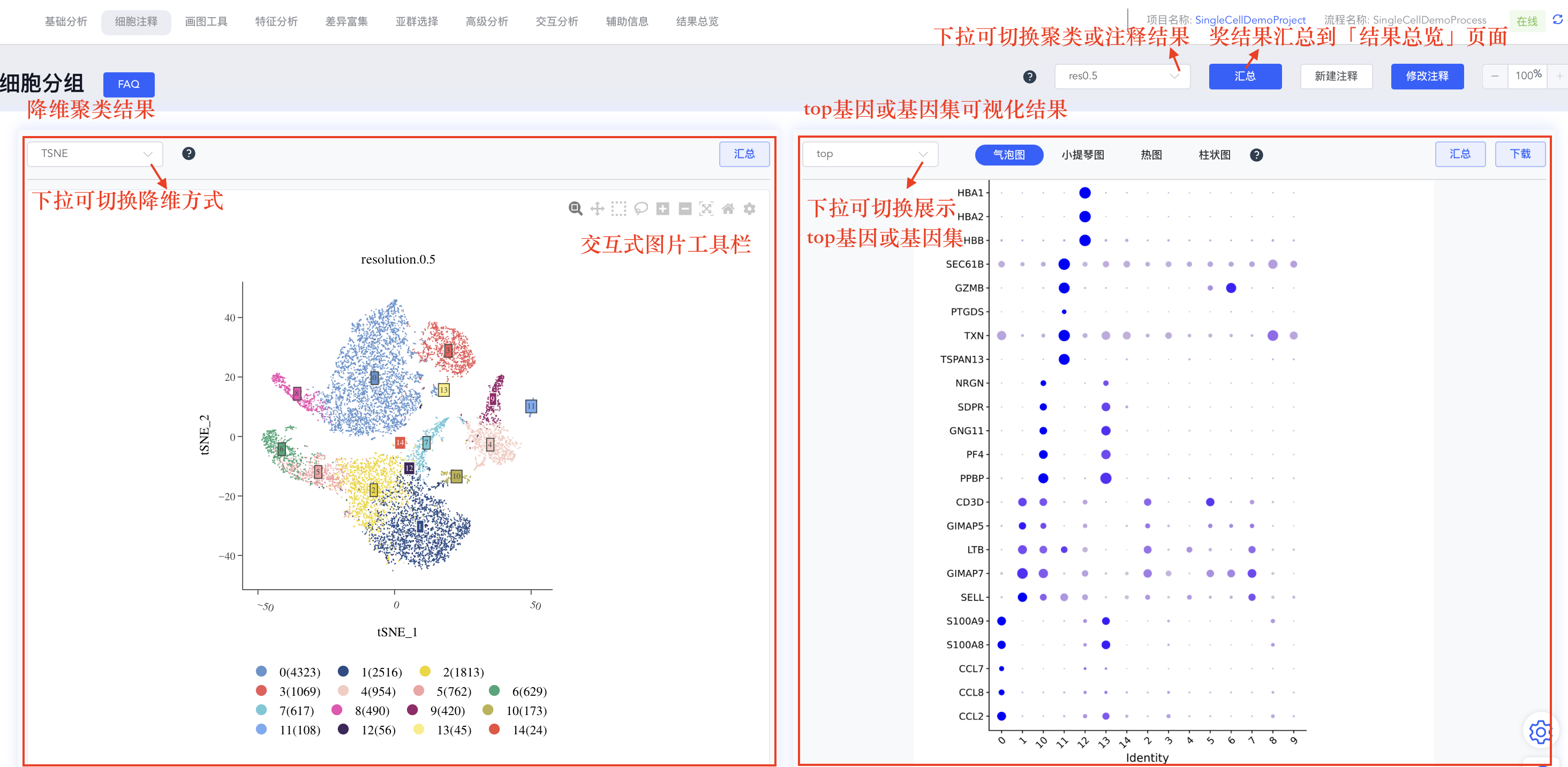
“细胞注释”模块主要包括四部分内容:降维聚类结果、top 基因或指定基因集的可视化结果、cluster 差异基因列表及差异基因的表达情况。点击选择降维聚类结果,界面中相关结果也会随之发生改变。
- 交互式降维聚类图:降维聚类结果包括 UMAP 和 tSNE 两种降维方式,降维聚类图为交互式图片,可使用鼠标更改 cluster 标签位置和查看 cluster 的细胞数。
- 差异基因可视化面板:每次更新聚类或注释结果时,均会计算每个 cluster 的差异基因列表,并对每个 cluster 的 top 5 (logFC 从大到小排序) 基因进行气泡图、小提琴图和热图可视化展示,以及每个样本中每组细胞的占比柱状图。
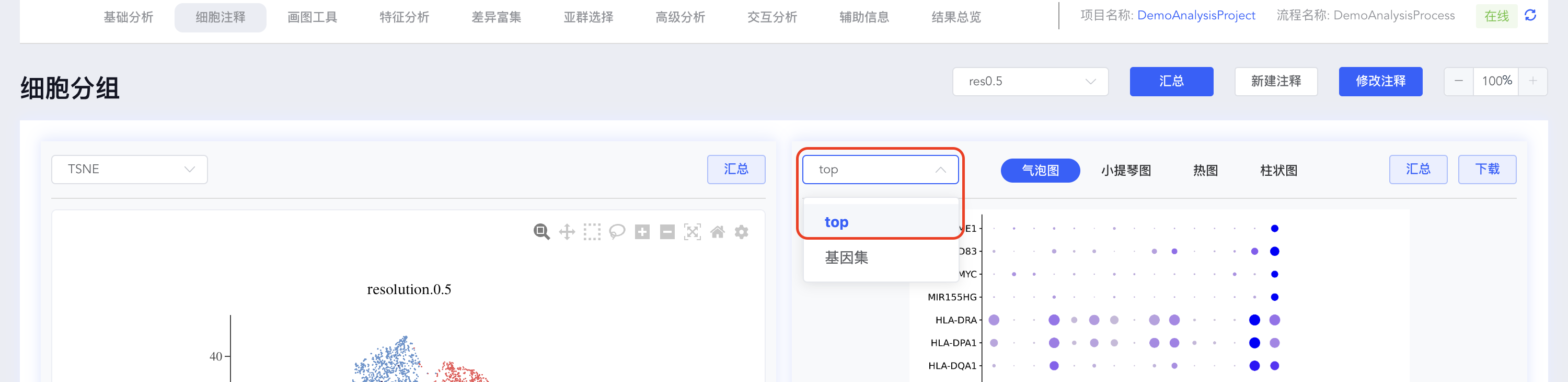
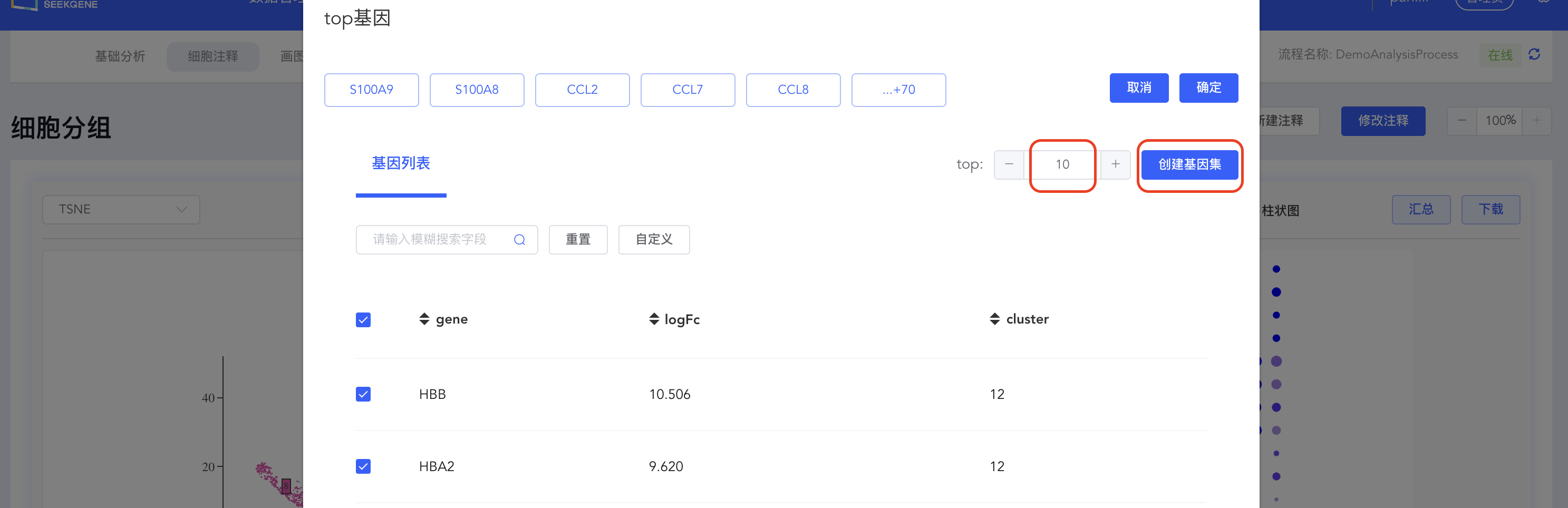
- 自定义 top 基因集:top 基因集可视化结果可自定义修改展示基因。点击【top】按钮,可在弹出窗口中修改用于可视化的基因,勾选或取消勾选对应基因后,点击【确定】即可对所选基因重新绘图;也可指定基因进行可视化展示,点击 top 下拉菜单中的【基因集】按钮,可从寻因数据库中选择相关基因集,也可点击分析流程基因集后的【+】自定义基因集进行可视化展示。
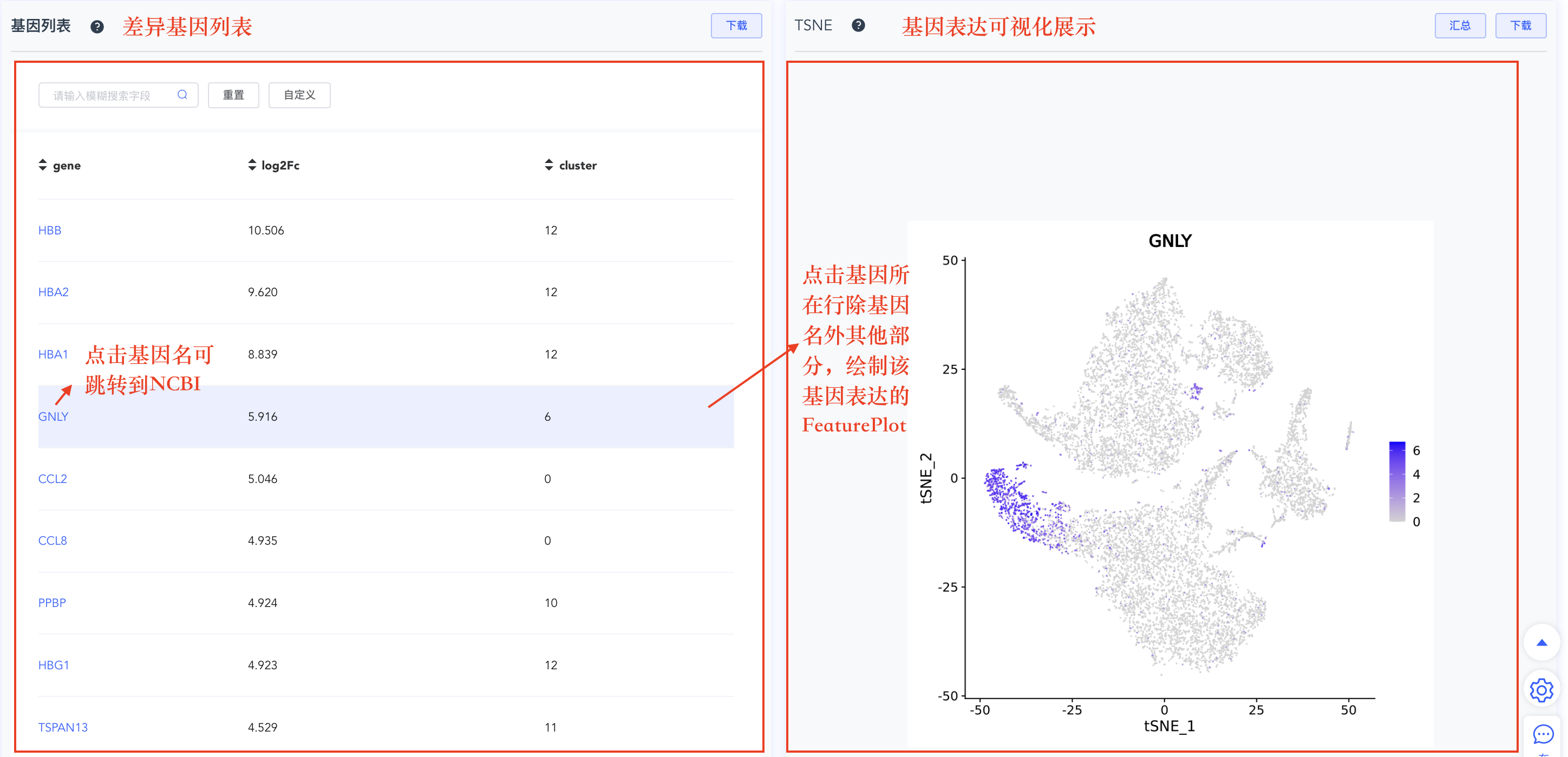
- 差异基因列表:基因列表记录所有基因在某个 cluster 或分组相对于其他细胞的 logFC 值。点击基因名称跳转到 NCBI 网站,点击基因所在行可绘制该基因的 FeaturePlot 图(位于列表右侧)。该列表默认按 logFC 从大到小排序,点击表头可自定义排列顺序。
TIP
平台所有的分析结果图,包括降维图、热图等,都可以轻松分享到「结果总览」页面,方便您集中查看、导出和报告。
注释策略
细胞注释 (Cell Annotation) 的核心任务是,根据每个细胞或细胞群的基因表达特征,识别出它们在生物学上的真实身份。主流的注释策略分为两大类:
基于标记基因的注释 (Marker-based Annotation)
这是最经典、最依赖专家知识的方法。研究人员根据已知的标记基因 (Marker) 列表,判断每个细胞 cluster 的身份。
- 优点:
- 可解释性强:结论直接基于公认的生物学标志物。
- 灵活性高:可根据研究的具体情境,调整和优化 Marker 列表。
- 能发现新细胞类型:对于无法被现有数据库匹配的未知细胞群,此方法是唯一有效的鉴定手段。
- 缺点:
- 主观性强:高度依赖研究者的先验知识,不同的人可能会有不同的判断。
- 知识局限性:对于研究不充分的组织或物种,可能缺乏可靠的 Marker 基因。
- 耗时耗力:需要手动检查大量基因的表达模式。
基于参考数据集的注释 (Reference-based Annotation)
该方法将待查询的单细胞数据与一个已经注释好的、高质量的参考图谱 (Reference Atlas) 进行比对,通过计算相似性来自动分配细胞身份。
- 优点:
- 客观、自动化:减少了人为干预,结果可重复性高。
- 高效快捷:能够快速对大规模数据集给出初步注释。
- 缺点:
- 依赖参考图谱质量:如果参考图谱本身不准确或不完整,会导致错误的注释。
- 无法识别新类型:只能识别出参考图谱中已存在的细胞类型。
IMPORTANT
在实践中,最佳策略是将两者结合。先使用自动化注释(如平台内置的 SingleR)获得一个快速、客观的基线结果,然后基于已知的 Marker 基因进行手动验证和精修。这既保证了效率,又确保了结果的准确性。
实操指南
自动注释
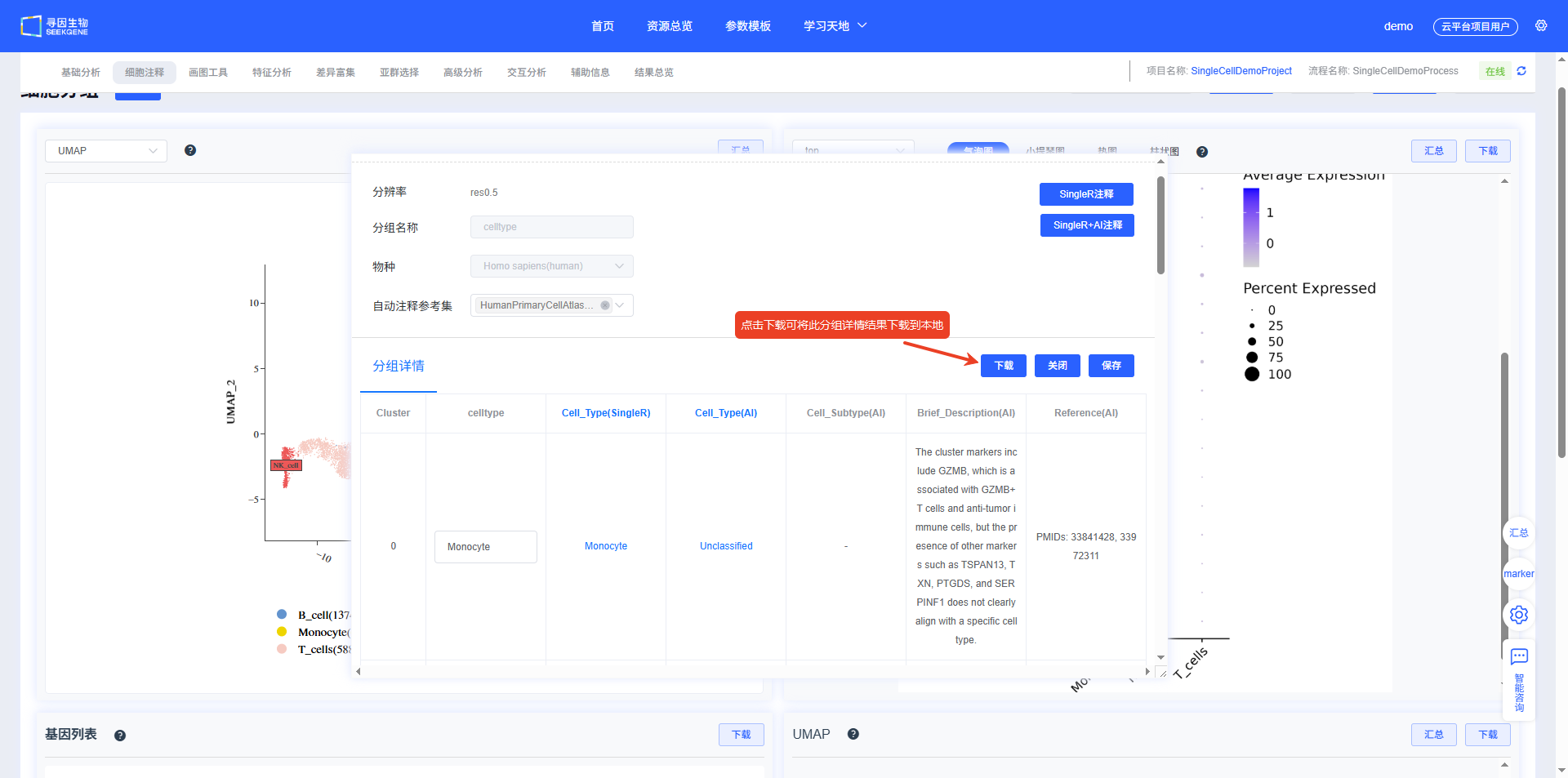
“细胞注释”模块可进行自动注释和手动注释。在完成“基础分析”后,会基于最小分辨率,使用 SingleR 软件及其参考集(人:HumanPrimaryCellAtlasData_main,小鼠和大鼠:ref_Mouse_all)进行自动注释,自动注释标签为 CellAnnotation。
- 首先下拉选择自动注释要使用的分辨率,然后点击【新建注释】,弹出添加分组弹窗,该弹窗可随意拖动位置(鼠标放置在可拖拽区域)和大小(鼠标放置在弹窗右下角)。
- 填写“分组名称”,并选择“自动注释参考集”,最后点击【自动注释】,自动刷新分析进度。
- 分析进度完成后,对应注释结果自动填充到分组详情表中。同时,降维图、top 基因可视化结果、基因列表和基因可视化图同步更新。注释完成后点击弹窗底部的【关闭】关闭弹窗。
- 点击同一分辨率下新增分组名称的注释标签,可进行结果切换。
- 当点击【Single + AI 注释】时,会得到 Single 和 AI 的注释结果,以及参考的 marker 描述和文献。
手动注释
手动注释是保证最终结果准确性的关键环节。当依据 cluster 间的差异基因或收集到的 marker 基因表达情况,需要输入或修改 cluster 注释结果时,可进行如下手动注释操作:
- 下拉选择手动注释要使用的分辨率,然后点击【新建注释】,弹出添加分组弹窗,该弹窗可随意拖动位置(鼠标放置在可拖拽区域)和大小(鼠标放置在弹窗右下角)。
- 填写“分组名称”,在分组详情中输入每个 cluster 对应的细胞类型。
- 每个 cluster 对应的细胞类型输入完成后,点击弹窗底部的【保存】,出现分析进度条,完成后点击【关闭】按钮关闭弹窗。
- 点击同一分辨率下新增分组名称的注释标签,可进行结果切换。
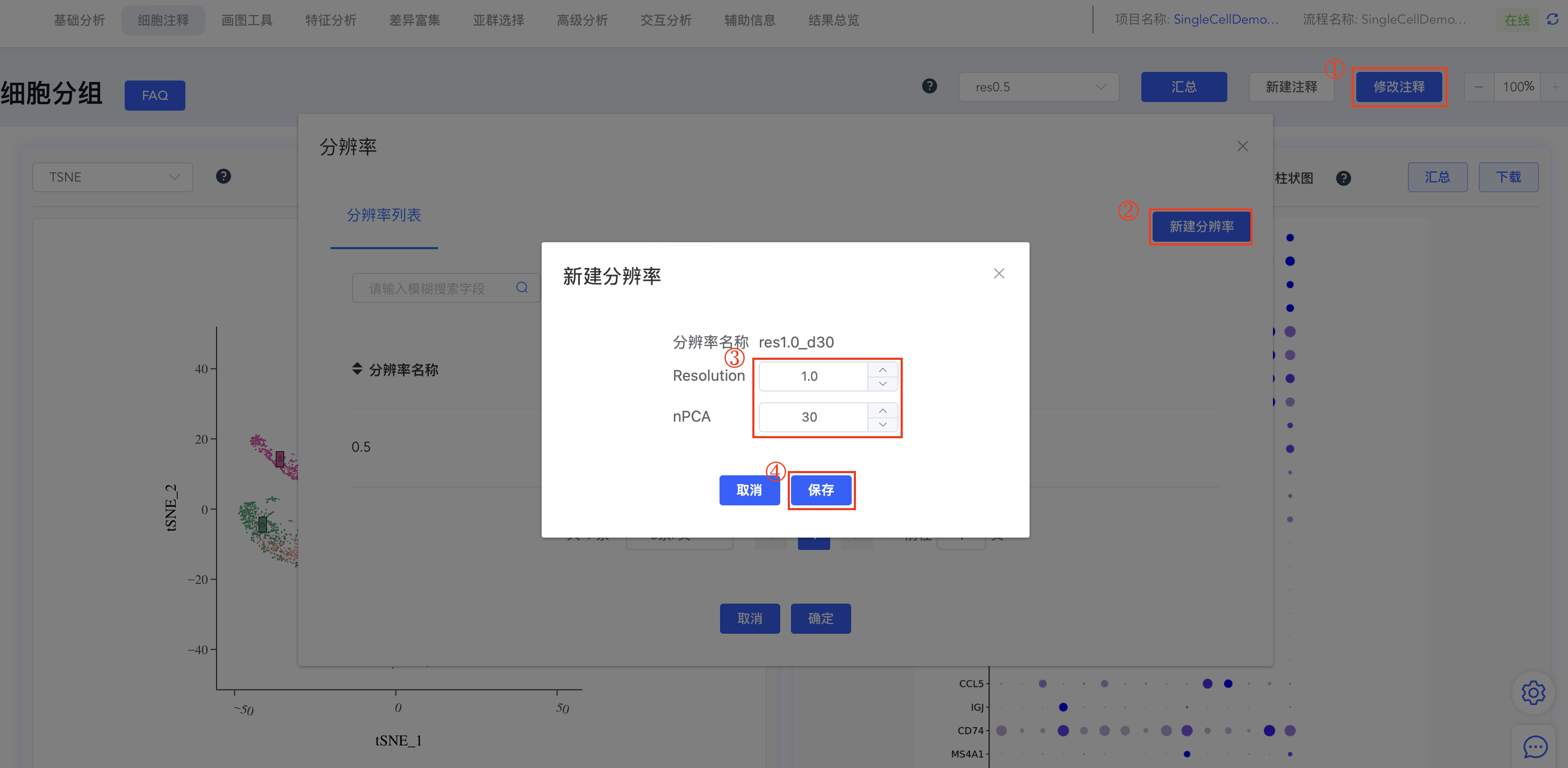
- 新建分辨率:
- 点击细胞分组中的【修改注释】弹出分辨率窗口,点击分辨率列表后的【+】弹出新增分辨率窗口,输入分辨率 (Resolution) 和 PC 数量 (nPCA) 后,点击【保存】,即可基于新的分辨率和 PC 数量重新进行聚类分析。完成后,细胞分组下拉框和分辨率列表均新增对应结果,点击细胞分组可进行结果切换。
- 修改注释结果:
- 点击细胞分组中的【修改注释】弹出分辨率窗口,点击分辨率对应的【编辑】可修改注释结果。如果该分辨率未做任何注释,则弹出“暂无分组”的提示信息;点击【删除】即可删除该分辨率及对应的细胞注释结果。
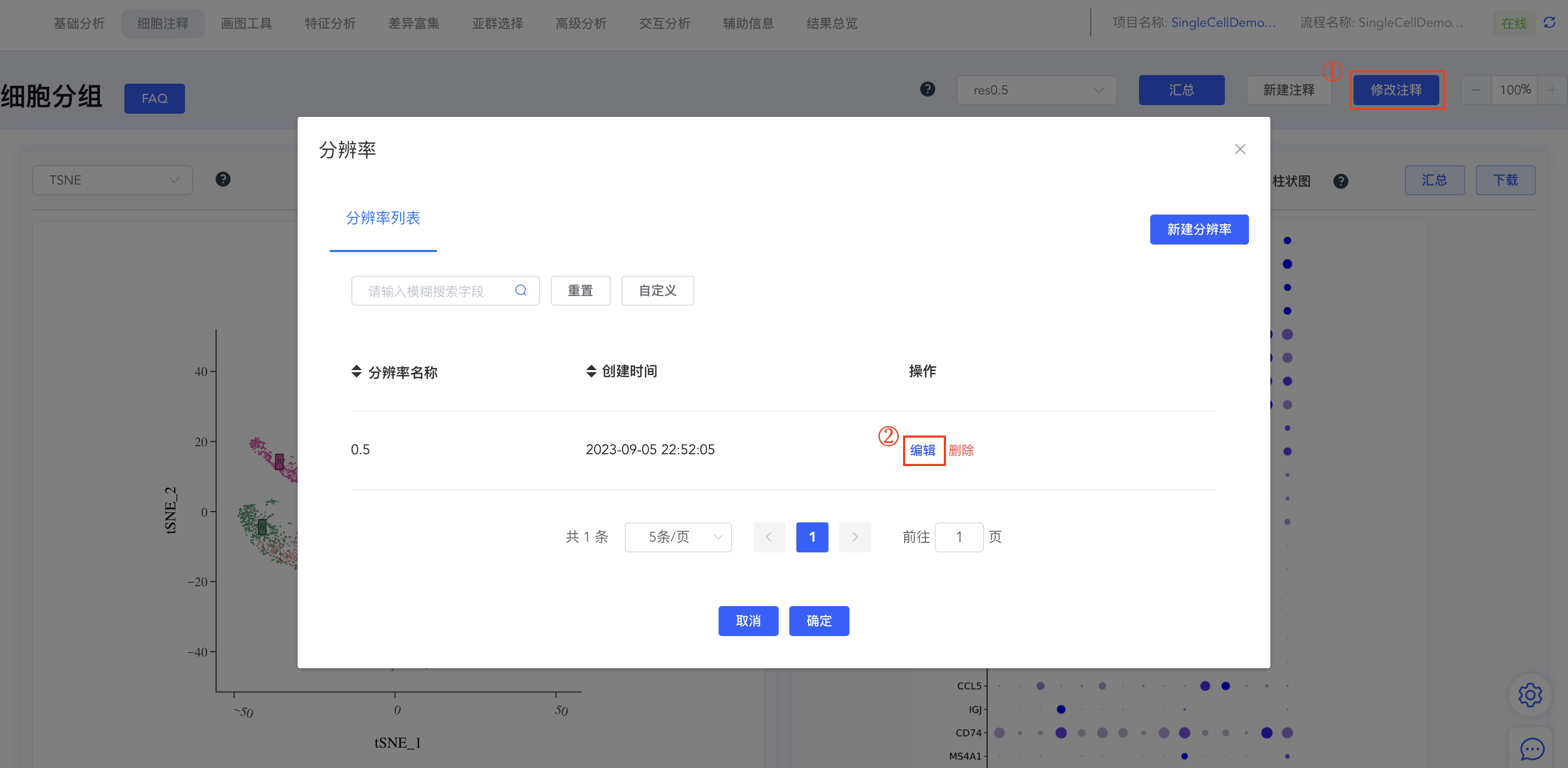
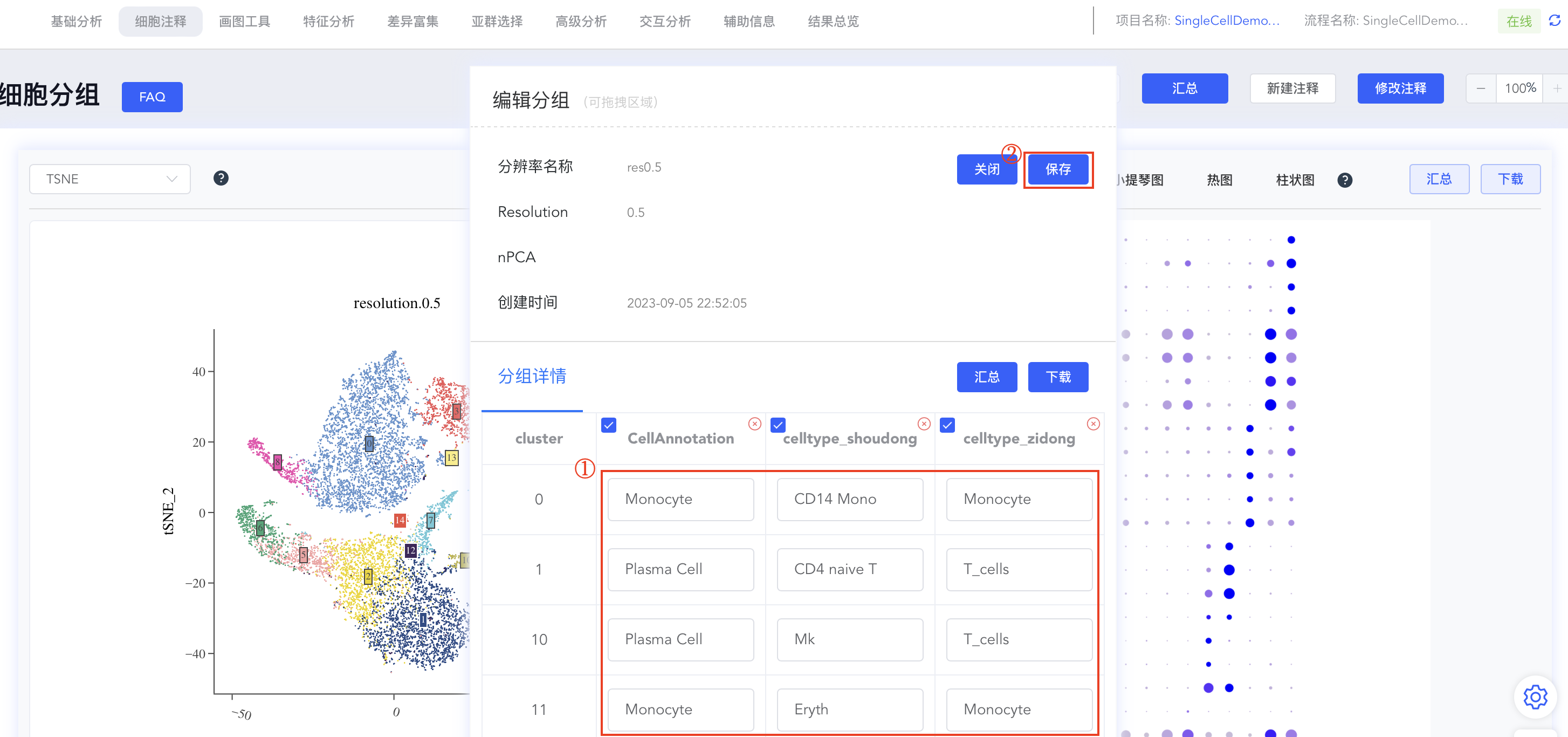
- 保存注释结果:
- 点击【编辑】后弹出编辑分组弹窗,分组详情中包括此分辨率下所有 cluster 的标注结果,可进行相应编辑,修改完成后点击【保存】同步结果。点击【x】可删除该分辨率下的该组注释结果。
TIP
可针对同一降维聚类结果多次注释并修改注释,比较不同方法和参考集的注释差异。
借助“寻小因”辅助注释
在手动注释过程中,研究者往往需要依赖先验知识和大量文献来确定细胞类型。为了提高注释的效率和准确性,“寻小因”智能助手为您提供了强大的支持。点击页面右下角侧栏的【智能咨询】,即可打开“寻小因”智能助手进入细胞注释界面。

什么是“寻小因”?
“寻小因”是平台内置的 AI 助手,它整合了海量生物学知识库。您可以通过自然语言对话,快速查询细胞标记基因、获取相关文献、解答生物学问题,从而辅助您完成细胞注释。
如何使用“寻小因”?
- 查询标记基因:当您对某个细胞群的身份不确定时,可以向“寻小因”提问。例如,您可以直接问:“耗竭 T 细胞的 marker 有哪些?”
- 获取参考信息:“寻小因”会返回相关的标记基因列表,并附上参考文献 (PMIDs),为您提供决策依据。
- 验证与注释:根据“寻小因”提供的信息,您可以在平台的“差异基因可视化面板”中检查这些基因的表达情况,以验证您的假设,并完成对细胞群的精准注释。
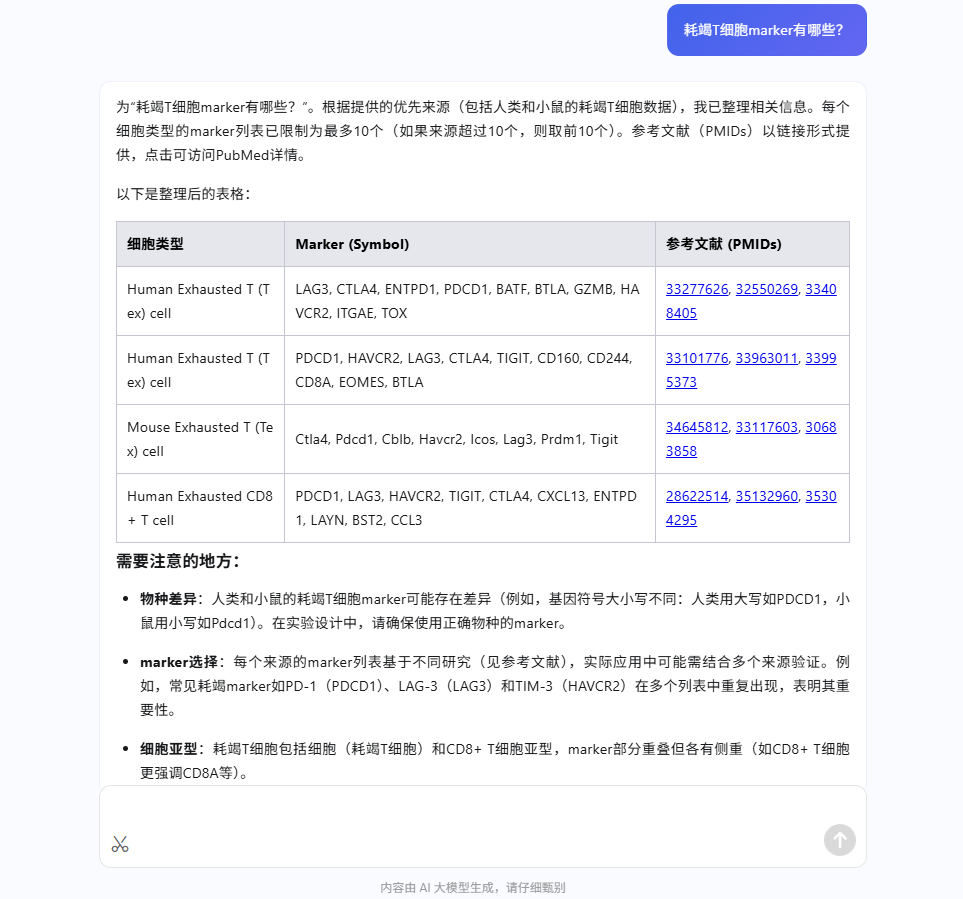
通过结合“寻小因”的智能问答与平台强大的可视化功能,您可以将手动注释的严谨性与 AI 的便捷性融为一体,显著提升研究效率。
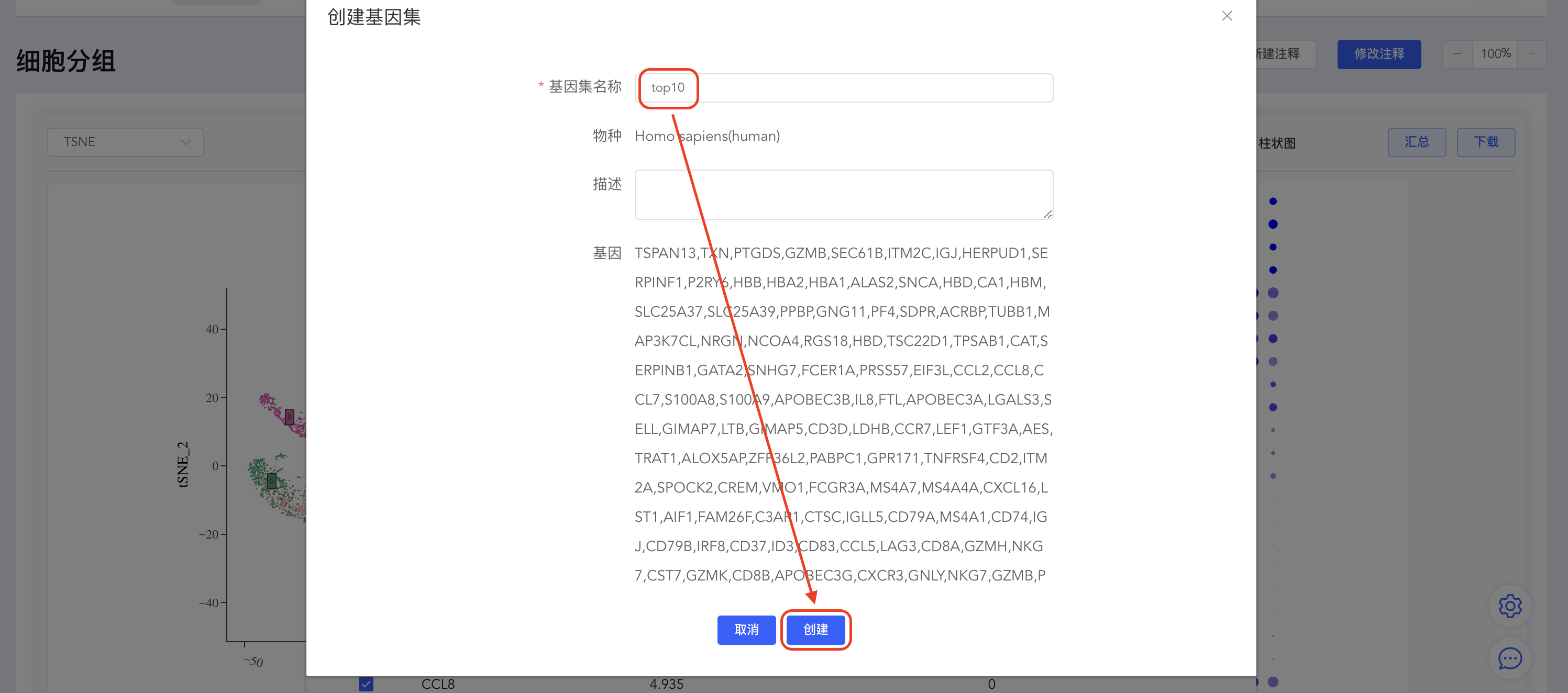
创建 top N 基因集
点击【top】按钮打开 top 基因界面,填写 top 基因数量(如 top 10),点击【创建基因集】,填写基因集名称,点击【创建】完成基因集的创建。
注意事项
当细胞数量过大时,热图会丢失 label 等信息,因此热图是经过降低数据量 (downsample) 绘制的,每个 cluster 或分组最多保留 500 个细胞。
为加快计算差异基因速度,该模块基因的 logFC 是基于 presto 包计算得到的,与 FindAllMarkers 或 FindMarkers 结果会存在些许差异,但两种方法计算出的基因呈线性相关。
特殊物种的注释可参考动植物特殊物种的单细胞注释方法讨论。
结果解读
一份高质量的细胞注释结果,需要从以下几个方面进行解读和评估:
- 降维图的一致性:在 UMAP/tSNE 图上,相同类型的细胞是否聚集在一起?不同类型细胞之间是否有清晰的界限?如果界限模糊,可能意味着这些细胞类型在转录组上本身就比较相似,或者需要调整聚类参数。
- Marker 基因的特异性:通过热图、小提琴图和 FeaturePlot,检查您的关键 Marker 基因是否在预期的细胞群中特异性高表达。例如,
CD4基因应该只在 CD4+ T 细胞中亮起。 - 细胞比例的合理性:注释出的各类细胞的比例是否符合样本的生物学背景?例如,在健康人的外周血中,淋巴细胞(T、B、NK 细胞)通常是主要成分。
- 生物学故事的完整性:最终的注释结果能否讲述一个通顺的生物学故事?例如,在肿瘤样本中,是否同时鉴定出了肿瘤细胞、免疫细胞和基质细胞,这符合肿瘤微环境的基本构成。
应用示例:肿瘤微环境中的 T 细胞亚群注释
- 背景:在一份肺癌组织的单细胞测序数据中,我们已经完成了大群注释,识别出了 T 细胞群体。
- 目标:深入分析 T 细胞的异质性,寻找可能影响免疫治疗效果的特定 T 细胞亚群。
- 方法:对 T 细胞群体进行亚群注释,结合经典 Marker (
CD4,CD8A,FOXP3,PDCD1(PD-1),CTLA4) 进行鉴定。 - 发现与解读:我们识别出了多个 T 细胞亚群,包括一个同时高表达
PDCD1和CTLA4的 CD8+ T 细胞亚群。这一发现揭示了肿瘤内存在一群功能耗竭的 T 细胞,这可能是导致免疫治疗效果不佳的原因之一,为后续研究提供了方向。