处理过程
表达文库分析
estep1: barcode/UMI 提取
转录组文库结构:
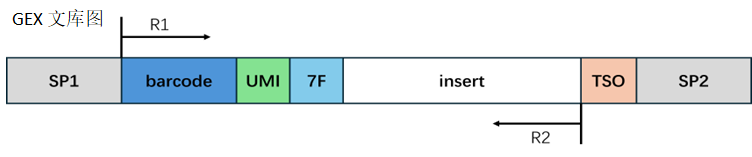
barcode 处理:
根据结构设计,取出相应序列。当取出的 barcode 序列在白名单中时,我们认为它是有效 barcode,计入有效 barcode 的 Reads 数量;当 barcode 不在白名单中时,我们认为它是无效 barcode。
TIP
测序过程中,有一定几率发生测序错误。在提供有白名单的情况下,SeekArc Tools v1.1.0 可以尝试 barcode 矫正。在启用矫正时,当无效 barcode 一个碱基错配(一个 hamming distance)的序列存在于白名单中:
- 只有唯一一个序列存在于白名单中:我们将这个无效 barcode 矫正为白名单中 barcode。
- 有多个序列存在于白名单中:我们将这个无效 barcode 改为 Reads 支持数量最多的序列。
接头处理:
在转录组中,Reads 2 的末端有可能会出现 7F 的反向互补序列,建库时可能引入的接头序列。我们对这些污染序列进行切除,剪切完的 Reads 2 长度需要大于设定的最小长度来保证有足够的信息,准确比对到基因组的位置。如果剪切完成后的 Reads 2 长度小于最小长度,我们认为这条 Reads 为无效 Reads。
estep2: 进行比对并找到比对基因
序列比对
- SeekArc Tools v1.1.0 使用STAR比对软件将处理后的 R2 比对到参考基因组上。
- SeekArc Tools v1.1.0 使用QualiMap软件和转录本注释文件 GTF,统计 Reads 比对外显子、内含子和基因间区等的比例。
- 使用featureCounts将比对上的 Reads 注释到基因上,可以选择不同的注释规则,如链方向性和定量的 feature。当使用外显子定量时,当 Reads 超过 50% 碱基比对到外显子区域时,认为该 Reads 来源于此外显子以及外显子对应的基因;当使用转录本定量时,当 Reads 超过 50% 碱基比对到转录本区域时,认为该 Reads 来源于此转录本以及转录本对应的基因。
经过上述处理后,有如下数据指标:
- Reads Mapped to Genome: 比对到参考基因组上的 Reads 占所有 Reads 的比例(包括只有一个比对位置和多个比对位置的 Reads)。
- Reads Mapped Confidently to Genome: 在参考基因组上只有一个比对位置的 Reads 占所有 Reads 的比例。
- Reads Mapped to Intergenic Regions:比对到基因间隔区 Reads 占所有 Reads 的比例。
- Reads Mapped to Intronic Regions:比对到内含子 Reads 占所有 Reads 的比例。
- Reads Mapped to Exonic Regions:比对到外显子 Reads 占所有 Reads 的比例。
estep3: 定量
UMI 定量:
SeekArc Tools v1.1.0 以 barcode 为单位提取 featureCounts 输出的 bam 数据,统计注释到基因的 UMI 和 UMI 对应的 Reads 数:
- 过滤掉对应 UMI 为单个重复碱基的 Reads,例如 UMI 为 TTTTTTTT。
- 当 Reads 注释到多个基因,在有唯一外显子的注释时,为有效 Reads,其他情形下都过滤掉。
UMI 矫正:
NOTE
测序过程中,UMI 也有一定概几率出现测序错误。SeekArc Tools v1.1.0 默认使用 UMI-tools 的adjacency方法对 UMI 进行矫正。
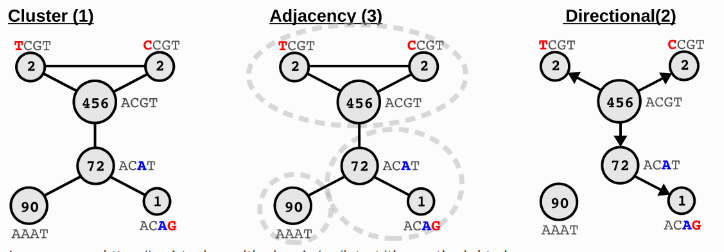
Image source: https://umi-tools.readthedocs.io/en/latest/the_methods.html
ATAC 文库分析
astep1: barcode 提取
ATAC 文库结构:

barcode 处理:
同 estep1 的处理方式一样。
接头和 Reads 处理:
在 ATAC 文库中,Reads 1 带有固定序列,末端有可能会出现接头序列;Reads 2 的末端有可能会出现固定序列的反向互补序列和接头序列。我们对这些污染序列进行切除,剪切完的 Reads 1 或 Reads 2 长度需要大于设定的最小长度来保证有足够的信息,准确比对到基因组的位置。如果剪切完成后的 Reads 1 或 Reads 2 长度小于最小长度,我们认为这条 Reads 为无效 Reads;如果剪切完成后的 Reads 1 或 Reads 2 长度大于 50,则截取 Reads 1 或 Reads 2 序列的前 50bp;如果剪切完成后的 Reads 1 或 Reads 2 长度小于 50 且大于最小长度,则保留 Reads 1 或 Reads 2 的全部序列。
astep2: 进行比对
序列比对:
使用 bwa mem 将处理后的 Reads 1 和 Reads 2 比对到参考基因组上。
astep3: 定量
使用 SnapATAC2 v2.8.0 处理 astep2 输出的 BAM 文件。
- 读取 BAM,获取 ATAC 的 Sequencing 和 Mapping 相关指标。
- 由 BAM 生成原始 fragments 文件。过滤掉线粒体相关的 fragments 后得到过滤后的 fragments 文件。
- 由过滤后的 fragments 文件生成 Anndata 对象。
- 绘制 TSS 得分分布图。
- 使用 MACS3 进行 call peak,并过滤重复的 peaks,输出到 peaks.bed。
- 根据 peaks 生成 raw_peaks_bc_matrix。
- 统计每个 barcode 的相关指标,输出到 per_barcode_metrics.csv。
- 绘制插入片段分布图。
- 细胞判定。
- 生成 filtered_feature_bc_matrix 和 filtered_peaks_bc_matrix。
- 统计 ATAC 的 Cells 和 Targeting 相关指标。
细胞判定
若指定 --min_atac_count 和 --min_gex_count:
- 则判定 barcode 中 UMI 数量大于 min_gex_count 值且 events 数量大于 min_atac_count 值的 barcode 为细胞。
若不指定:
- 首先,保留 barcode 中 UMI 数量大于 1 或 events in peaks 数量大于 1 的 barcode。
- 然后,过滤 "the fraction of fragments overlapping called peaks" 小于 "the fraction of genome in peaks" (将 peaks 的范围前后延伸 2kb,如果延伸后的 peak 有重叠则合并两个 peak 的范围)的 barcode。
- 去除重复值。将具有相同 UMI 值和 events in peaks 值的 barcode 过滤。
- 将过滤后的 barcode 的 UMI 值和 events in peaks 值进行 log10 转换。
- 根据转换后的 UMI 值和 events in peaks 值,使用 KMeans 算法将 barcode 分为两群其中均值高的群为细胞,另一群则不是细胞。
- 将去重过滤掉的 barcode 通过判定的 barcode 映射为细胞或非细胞。
- 设置最大细胞数为 20000。
astep4: 后续分析
经过上述步骤,得到细胞的表达矩阵和 ATAC 矩阵后,我们可以进行下一步的分析。
使用 Signac v1.14.0 将细胞的表达矩阵和 ATAC 矩阵合并为一个 seurat object,过滤不在数据库中的 feature,分别对表达矩阵和 ATAC 矩阵进行归一化、寻找高变基因、降维聚类之后寻找差异基因,进行 WNN 分群,最后计算 feature link。