SeekSoul Tools v1.2.2
SeekSoul Tools v1.2.2 is a software developed by SEEKGENE for processing single-cell transcriptome data. Currently, the software contains four modules:
rna module: This module is used for identifying cell barcodes, genome alignment and gene quantification to obtain a feature-barcode matrix for downstream analysis, followed by cell clustering and differential analysis. This module not only supports data from SeekOne® series kits but also supports various custom structure designs through barcode descriptions.
fast module: This module is specifically designed for data produced by the SeekOne® DD Single Cell Full-length RNA Sequence Transcriptome-seq Kit, used for barcode extraction, paired-end read alignment, quantification, and unique metrics analysis for full-length transcriptome data.
vdj module: This module is specifically designed for data produced by the SeekOne® DD Single Cell Immune Profiling Kit, used for assembling, filtering, and annotating immune receptors.
utils module: This module contains additional utility tools.
Software Download
SeekSoul Tools v1.2.2
Download-SeekSoulTools - md5: af52b5d936b60c740b239301f2026aba
wget download method:
mkdir seeksoultools.1.2.2
cd seeksoultools.1.2.2
wget -c -O seeksoultools.1.2.2.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/seeksoultools/seeksoultools.1.2.2.tar.gz"curl download method:
mkdir seeksoultools.1.2.2
cd seeksoultools.1.2.2
curl -C - -o seeksoultools.1.2.2.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/seeksoultools/seeksoultools.1.2.2.tar.gz"Software Installation
IMPORTANT
Before installation, ensure your system meets the requirements and has sufficient disk space. The first-time initialization may take longer than usual.
Installation:
# decompress
tar zxf seeksoultools.1.2.2.tar.gz
# set environment variables
export PATH=`pwd`:$PATH
echo "export PATH=$(pwd):\$PATH" >> ~/.bashrc
# initialization and installation verification
./seeksoultools --versionUsage Guide
rna module
Data Preparation
NOTE
Before starting the analysis, ensure you have prepared the following required files:
- Sequencing data (FASTQ format)
- Reference genome for the corresponding species
- Gene annotation file (GTF format)
Download Sample Datasets
Sample Datasets - md5: 3d15fcfdefc0722735d726f40ec4e324 (Species: Human)
wget download method:
wget -c -O demo_dd.tar "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/demo_dd.tar"
# decompress
tar xf demo_dd.tarcurl download method:
curl -C - -o demo_dd.tar "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/demo_dd.tar"
# decompress
tar xf demo_dd.tarDownload and Build Reference Genome
Download-human-reference-GRCh38 - md5: 5473213ae62ebf35326a85c8fba6cc42
Download-mouse-reference-mm10 - md5: 5c7c63701ffd7bb5e6b2b9c2b650e3c2
wget download method:
wget -c -O GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/GRCh38.tar.gz"
# decompress
tar -zxvf GRCh38.tar.gz
wget -c -O mm10.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10_ensemble_102.tar.gz"
tar -zxvf mm10.tar.gzcurl download method:
curl -C - -o GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/GRCh38.tar.gz"
# decompress
tar -zxvf GRCh38.tar.gz
curl -C - -o mm10.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10_ensemble_102.tar.gz"
tar -zxvf mm10.tar.gzFor reference genome construction, please refer to How to build reference genome?
Running
Run Examples
TIP
SeekSoulTools provides multiple running modes for different analysis needs. The following examples cover the most common use cases. Choose the appropriate parameter combinations based on your specific requirements.
Example 1: Basic Usage
Set up the necessary configuration files for analysis, including sample data paths, chemistry version, genome index, GTF, etc. Run SeekSoulTools using the following command:
seeksoultools rna run \
--fq1 /path/to/demo_dd/demo_dd_S39_L001_R1_001.fastq.gz \
--fq2 /path/to/demo_dd/demo_dd_S39_L001_R2_001.fastq.gz \
--samplename demo_dd \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--chemistry DDV2 \
--core 4 \
--include-intronsExample 2: Specify a Different Version of STAR for Analysis
To use a specific version of STAR for analysis while ensuring compatibility with the --genomeDir generated by that version, run SeekSoulTools with the path to the desired STAR version:
seeksoultools rna run \
--fq1 /path/to/demo_dd/demo_dd_S39_L001_R1_001.fastq.gz \
--fq2 /path/to/demo_dd/demo_dd_S39_L001_R2_001.fastq.gz \
--samplename demo_dd \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--chemistry DDV2 \
--core 4 \
--include-introns \
--star_path /path/to/cellranger-5.0.0/lib/bin/STARExample 3: Multiple FASTQ Files for One Sample
If a sample has multiple FASTQ datasets, provide the paths to all FASTQ files associated with that sample:
seeksoultools rna run \
--fq1 /path/to/demo_dd_S39_L001_R1_001.fastq.gz \
--fq1 /path/to/demo_dd_S39_L002_R1_001.fastq.gz \
--fq2 /path/to/demo_dd_S39_L001_R2_001.fastq.gz \
--fq2 /path/to/demo_dd_S39_L002_R2_001.fastq.gz \
--samplename demo \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--chemistry DDV2 \
--core 4 \
--include-intronsExample 4: Custom R1 Structure
To customize the structure of Read 1 (R1) FASTQ files:
seeksoultools rna run \
--fq1 /path/to/demo_dd_S39_L001_R1_001.fastq.gz \
--fq2 /path/to/demo_dd_S39_L001_R2_001.fastq.gz \
--samplename demo \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--barcode /path/to/utils/CLS1.txt \
--barcode /path/to/utils/CLS2.txt \
--barcode /path/to/utils/CLS3.txt \
--linker /path/to/utils/Linker1.txt \
--linker /path/to/utils/Linker2.txt \
--structure B9L12B9L13B9U8 \
--core 4 \
--include-intronsB9L12B9L13B9U8represents the Read1 structure: 9 bases barcode + 12 bases linker + 9 bases barcode + 13 bases linker + 9 bases barcode + 8 bases UMI. The total cell barcode has 3 segments, totaling 27 bases (9*3), and the UMI is 8 bases.- Use --barcode to specify the three barcode segments and --linker to specify the two linker segments sequentially.
Parameter Descriptions
IMPORTANT
The following parameters significantly impact analysis results. Please choose carefully based on your experimental design and data characteristics:
- --chemistry: Must match exactly with the kit type used
- --include-introns: Affects gene expression quantification strategy
- --expectNum: Affects cell number estimation
| Parameters | Descriptions |
|---|---|
| --fq1 | Paths to R1 fastq files. |
| --fq2 | Paths to R2 fastq files. |
| --samplename | Sample name. A directory will be created with this name in the outdir directory. Only digits, letters, and underscores are supported. |
| --outdir | Output directory. Default: ./ |
| --genomeDir | Path to the reference genome generated by STAR. Version must be consistent with the STAR used by SeekSoulTools. |
| --gtf | Path to the GTF file for the corresponding species. |
| --core | Number of threads used for analysis. |
| --chemistry | Reagent type, each corresponding to a combination of --shift, --pattern, --structure, --barcode, and --sc5p. Available options: DDV2, DD5V1, MM, MM-D. DDV2: SeekOne® DD Single Cell 3' Transcriptome-seq Kit DD5V1: SeekOne® DD Single Cell 5' Transcriptome-seq Kit MM: SeekOne® MM Single Cell Transcriptome Kit MM-D: SeekOne® MM Large-well Single Cell Transcriptome-seq Kit |
| --skip_misB | Disallow barcode base mismatches. Default allows one base mismatch. |
| --skip_misL | Disallow linker base mismatches. Default allows one base mismatch. |
| --skip_multi | Discard reads that can be corrected to multiple white-listed barcodes. Default corrects to the barcode with highest frequency. |
| --expectNum | Estimated number of captured cells. |
| --forceCell | When normal analysis yields unsatisfactory cell numbers, use this parameter followed by an expected value N. SeekSoulTools will take the top N cells by UMI count. |
| --include-introns | When disabled, only exon reads are used for quantification; when enabled, intron reads are also used. |
| --star_path | Specify path to alternative STAR version for alignment. Version must be compatible with --genomeDir. Default uses STAR from environment. |
Output Descriptions
Here's the output directory structure: each line represents a file or folder, indicated by "├──", and the numbers indicate three important output files.
./
├── demo_report.html 1
├── demo_summary.csv 2
├── demo_summary.json
├── step1
│ └──demo_2.fq.gz
├── step2
│ ├── featureCounts
│ │ └── demo_SortedByName.bam
│ └── STAR
│ ├── demo_Log.final.out
│ └── demo_SortedByCoordinate.bam
├── step3
│ ├── filtered_feature_bc_matrix 3
│ └── raw_feature_bc_matrix
└──step4
├── FeatureScatter.png
├── FindAllMarkers.xls
├── mito_quantile.xls
├── nCount_quantile.xls
├── nFeature_quantile.xls
├── resolution.xls
├── top10_heatmap.png
├── tsne.png
├── tsne_umi.png
├── tsne_umi.xls
├── umap.png
└── VlnPlot.png- Final report in html
- Quality control information in csv
- Filtered feature-barcode matrix
Algorithms Overview
step1: barcode/UMI extraction
SeekSoulTools is able to extract the barcode and UMI sequences based on different Read1 structures. The pipeline processes the barcodes and filters Read1 and its corresponding Read2, and an updated fastq file is generated at the end of step 1.
Structure design and description
Barcode and UMI descriptions: Describing the basic structure of Read1 using letters and numbers, where the letters represent the meaning of the nucleotides and the numbers represent the length of the nucleotides.
B: barcode bases L: linker bases U: UMI bases X: other arbitrary bases used as placeholders
Taking the following two Read1 structures as examples: B8L8B8L10B8U8:

B17U12:

Anchor-based misalignment design: In MM design, to increase the base balance of the linker portion during sequencing,1-4 bp shifted bases, called anchors, were added. The anchor determines the starting position of the barcode.

Workflow
Anchor determination:
For data with misaligned Read1 (produced by MM reagents), SeekSoulTools attempts to find the anchor sequence within the first 7 bases of the Read1 sequence to determine the start position of subsequent barcodes. If the anchor sequence is not found, the corresponding Read1 and R2 are considered invalid reads.
Barcode and linker correction:
After determining the starting position of the barcode, the corresponding sequence is extracted based on the structural design. When the extracted barcode sequence is found in the whitelist, it is considered a valid barcode and the read count with valid barcodes is recorded. When the barcode is not found in the whitelist, it is considered an invalid barcode.
During sequencing process, there is a certain probability that sequencing error occurs. With the presense of a whitelist, SeekSoulTools are able to do barcode correction. When correction is enabled, if sequences that are one base differ (one humming distance apart) from the invalid barcode appear in the whitelist, we will consider the following circumstances:
- If there is one and only sequence exists in the whitelist, we will correct the invalid barcode to the barcode in the whitelist.
- If multiple sequences exist in the whitelist, we will correct the invalid barcode to the sequence with the highest read support.
The logic of linker correction is the same as that of barcode correction.
Adaptors and polyA sequence trimming
In transcriptome, polyA tail and Adapter sequences introduced during library preparation, may appear at the end of Read2.We remove these contaminating sequences and make sure the trimmed Read2 length is greater than the minimum length for accurate alignment afterward. If the trimmed Read2 length is less than the minimum length, we consider the read to be invalid.
After the processing procedure described above, the data composition is shown in the following figure:
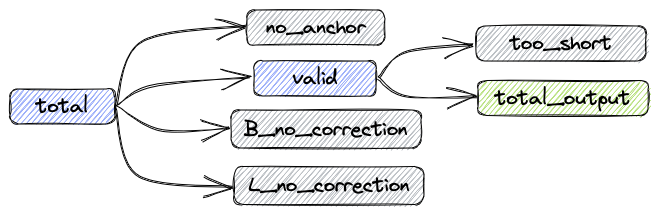
- total: Total reads
- valid: Number of reads without correction and number of successfully corrected reads
- B_corrected: Number of successfully corrected reads
- B_no_correction: Number of reads with incorrect barcodes
- L_no_correction: Number of reads with incorrect linkers
- no_anchor:Number of reads without anchors
- trimmed: Number of reads that have been trimmed
- too_short: Number of reads that are shorter than 60bps after trimming
The relationships between the metrics are as follows:
total = valid + no_anchor + B_no_correction + L_no_correction
Number of reads in the updated FASTQ file: total_output = valid - too_short
step2: Alignment
Sequence Alignment
- SeekSoulTools uses an aligner software called STAR to perform splicing-aware alignment of reads to the genome.
- After the alignment procedure has mapped the reads to the genome, SeekSoulTools uses another software called QualiMap along with a gene annotation transcript file GTF to bucket the reads into exonic, intronic, and intergenic regions.
- Using featureCounts, the reads aligned to the genome were annotated to genes, with different rules such as strand specificity and features used for annotation. When using exon for annotation, a read is annotated to the corresponding gene if over 50% of its bases are aligned to the exon. When using transcripts for annotation, a read is annotated to the corresponding gene if over 50% of its bases are aligned to the transcript.
After the processing procedure described above, the metrics is shown below:
- Reads Mapped to Genome: Fraction of reads that aligned to the genome (including both uniquely mapped reads and multi-mapped reads)
- Reads Mapped Confidently to Genome: Fraction of reads that uniquely mapped to the genome
- Reads Mapped to Intergenic Regions:Fraction of reads that mapped to intergenic regions
- Reads Mapped to Intronic Regions:Fraction of reads that mapped to intronic regions
- Reads Mapped to Exonic Regions:Fraction of reads that mapped to exonic regions
step3: Counting
UMI counting
SeekSoulTools extracts group of reads that shared the same barcode from output BAM file and counts the number of UMIs annotated to genes and the number of reads corresponding to each UMI.
- Filter out reads whose UMIs consist of repetitive bases. For example, TTTTTTTT.
- If a read has multiple annotations and only one gene annotation is from exon, it is considered a valid read, and all others are filtered.
UMI correction
UMIs may also have sequencing errors during sequencing process. By default, SeekSoulTools uses the adjacency from UMI-tools to correct UMIs.
 Image source: https://umi-tools.readthedocs.io/en/latest/the_methods.html
Image source: https://umi-tools.readthedocs.io/en/latest/the_methods.html
Cell calling
In a cell population, we assume that the mRNA content of cells does not differ significantly. If the mRNA content of a barcode is very low, we consider that barcode might be 'empty', and the mRNA comes from the background. SeekSoulTools uses the following steps to determine whether a barcode has a cell:
- Sort all barcodes in descending order based on their corresponding UMI counts.
- The threshold is calculated by dividing the number of UMIs for the barcode at the 1% position of the estimated cells by 10.
- Barcodes with UMIs greater than the threshold are considered to be cells.
- If the UMI of a barcode is less than the threshold but greater than 300, DropletUtils is used for further analysis. The DropletUtils method first assumes that barcodes with UMI counts below 100 are empty droplets. It then uses the total UMI count for each gene in each droplet as the expected UMI count for that gene in the background RNA expression profile. Next, it performs a statistical test on the UMI counts of each barcode, identifying those with significant differences as cells.
- Those do not meet the above criteria are considered as background.
After the processing procedure described above, the metrics is shown below:
- Estimated Number of Cells: Total number of cells by cell calling
- Fraction Reads in Cells: Fraction of reads after cell calling among all reads used for counting
- Mean Reads per Cell: Average number of reads per cell, Total number of reads/Number of cells after cell calling
- Median Genes per Cell: Median gene count in barcodes after cell calling
- Median UMI Counts per Cell: Median UMI count in barcodes after cell calling
- Total Genes Detected: Number of genes detected in all cells
- Sequencing Saturation: 1 - Total UMI count/Total read count
step4: Downstream analysis
SeekSoulTools perform downstream analysis when we have gene expression matrix from step3.
Seurat analysis
SeekSoulTools use Seurat to calculate the mitochondrial content, number of genes, and UMIs of each cell. After that, the gene expression matrix is normalized, and a subset of features that exhibit high cell-to-cell variation in the dataset is identified. Linear dimensional reduction using PCA is then performed, and the result is passed to t-SNE and UMAP for visualization. A graph-based clustering procedure is then followed, and cells are partitioned into different clusters. Finally, SeekSoulTools finds markers that define clusters via differential expression.
fast module
Data preparation
Download sample datasets
sample datasets - md5: 878de2833feea2deb7d79224409d0d09(Species: Homo sapiens.)
wget
wget -c -O cellline.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/cellline.tar.gz"
# decompress
tar zxf cellline.tar.gzcurl
curl -C - -o cellline.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/cellline.tar.gz"
# decompress
tar zxf cellline.tar.gzDownload and assembly of reference genome
Download-human-reference-GRCh38 - md5: 5473213ae62ebf35326a85c8fba6cc42
Download-hg38-rRNA - md5: 9949f6cea38633daf1d5bf1a2b976488
Download-mouse-reference-mm10 - md5: 5c7c63701ffd7bb5e6b2b9c2b650e3c2
Download-mouse-rRNA - md5: 7a1c2d573086fa9240c8978bb8a859f7
wget
wget -c -O GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/GRCh38.tar.gz"
# decompress
tar -zxvf GRCh38.tar.gz
wget -c -O hg38_rRNA.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/hg38_rRNA.tar.gz"
tar -zxvf hg38_rRNA.tar.gz
wget -c -O mm10.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10.tar.gz"
tar -zxvf mm10.tar.gz
wget -c -O mouse_rRNA.tar.gz "http://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10_rRNA.tar.gz"
tar -zxvf mouse_rRNA.tar.gzcurl
curl -C - -o GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/GRCh38.tar.gz"
# decompress
tar -zxvf GRCh38.tar.gz
curl -C - -o hg38_rRNA.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/hg38_rRNA.tar.gz"
tar -zxvf hg38_rRNA.tar.gz
curl -C - -o mm10.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10.tar.gz"
tar -zxvf mm10.tar.gz
curl -C - -o mouse_rRNA.tar.gz "http://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/mm10_rRNA.tar.gz"
tar -zxvf mouse_rRNA.tar.gzThe assembly of the reference genome refers toHow to build reference genome?
Run SeekSoulTools
Run tests
Example 1: single cell full length RNA sequence data
Set up the necessary configuration files for the analysis, including the paths to the sample data, the chemistry versions, the genome index, the gene annotation file, etc. Run the SeekSoulTools using the following command:
seeksoultools fast run \
--fq1 /path/to/cellline/cellline_R1.fq.gz \
--fq2 /path/to/cellline/cellline_R2.fq.gz \
--samplename demo \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--chemistry DD-Q \
--include-introns \
--core 4Example 2: Single-cell transcriptomic data from FFPE samples, using parameters --scoremin 0.2 --matchnmin 0.33
seeksoultools fast run \
--fq1 /path/to/ffpe/ffpe_R1.fq.gz \
--fq2 /path/to/ffpe/ffpe_R2.fq.gz \
--samplename demo \
--genomeDir /path/to/GRCh38/star \
--gtf /path/to/GRCh38/genes/genes.gtf \
--scoremin 0.2 \
--matchnmin 0.33 \
--chemistry DD-Q \
--include-introns \
--core 4Parameter descriptions
| Parameters | Descriptions |
|---|---|
| --fq1 | Paths to R1 fastq files. |
| --fq2 | Paths to R2 fastq files. |
| --samplename | Sample name. A directory will be created named after the sample name in the outdir directory. Only digits, letters, and underscores are supported. |
| --outdir | Output directory. Default: ./ |
| --genomeDir | The path of the reference genome generated by STAR. The version needs to be consistent with the STAR used by SeekSoulTools. |
| --gtf | Path to the GTF file for the corresponding species. |
| --rRNAgenomeDir | The path to the reference genome generated by STAR, which is used for evaluating rRNA portion. The version needs to be consistent with the STAR used by SeekSoulTools. |
| --rRNAgtf | Path to the GTF file for the corresponding species, which is used for evaluating rRNA portion. |
| --core | Number of threads used for the analysis |
| --chemistry | Reagent type, with each type corresponding to a combination of--shift,--pattern,--structure,--barcode and --sc5p.Available options: DD-Q.DD-Q corresponds to the SeekOne™ DD Single Cell Full-length RNA Sequence Transcriptome-seq Kit. |
| --skip_misB | If enabled, no base mismatch is allowed for barcode. Default is 1. |
| --skip_misL | If enabled, no base mismatch is allowed for linker. Default is 1. |
| --skip_multi | If enabled, discard reads that can be corrected to multiple white-listed barcodes. Barcodes are corrected to the barcode with the highest frequency by default. |
| --expectNum | Estimated number of captured cells. |
| --forceCell | When the number of cells obtained from analysis is abnormal, add this parameter with expected value N. SeekSoulTools will select the top N cells based on UMI from high to low. |
| --include-introns | When disabled, only exon reads are used for quantification. When enabled, intron reads are also used for quantification. |
| --star_path | Path to another version of STAR for alignment. The version must be compatible with the--genomeDir version. The default--star_pathis the STAR in the environment. |
| --scoremin | Set--outFilterScoreMinOverLreadparameter of STAR. By adjusting the value, you can modify the alignment criteria for mapping reads to the reference genome for FFPE sample. |
| --matchnmin | Set--outFilterMatchNminOverLreadparameter of STAR. By adjusting the value, you can modify the alignment criteria for mapping reads to the reference genome for FFPE sample. |
Output descriptions
Here's the output directory structure: each line represents a file or folder, indicated by "├──", and the numbers indicate three important output files.
.
├── PBMC_report.html
├── PBMC_summary.csv
├── PBMC_summary.json
├── step1
│ ├── PBMC_1.fq.gz
│ ├── PBMC_2.fq.gz
│ ├── PBMC_multi_1.fq.gz
│ ├── PBMC_multi_2.fq.gz
│ └── PBMC_multi.json
├── step2
│ ├── featureCounts
│ │ ├── counts.txt
│ │ ├── counts.txt.summary
│ │ └── PBMC_SortedByName.bam
│ └── STAR
│ ├── downbam
│ │ ├── log.txt
│ │ ├── PBMC.bed
│ │ ├── PBMC.down.0.1.bam
│ │ ├── PBMC.down.0.1.bam.bai
│ │ ├── PBMC.geneBodyCoverage.curves.pdf
│ │ ├── PBMC.geneBodyCoverage.r
│ │ ├── PBMC.geneBodyCoverage.txt
│ │ └── PBMC.reduction.bed
│ ├── PBMC_Log.final.out
│ ├── PBMC_Log.out
│ ├── PBMC_Log.progress.out
│ ├── PBMC_SJ.out.tab
│ ├── PBMC_SortedByCoordinate.bam
│ ├── PBMC_SortedByCoordinate.bam.bai
│ ├── PBMC_SortedByName.bam
│ ├── PBMC__STARtmp
│ ├── report.pdf
│ ├── rnaseq_qc_results.txt
│ └── rRNA
│ ├── counts.txt
│ ├── counts.txt.summary
│ ├── PBMC_Aligned.out.bam
│ ├── PBMC_Aligned.out.bam.featureCounts.bam
│ ├── PBMC_Log.final.out
│ ├── PBMC_Log.out
│ ├── PBMC_Log.progress.out
│ ├── PBMC_SJ.out.tab
│ ├── PBMC__STARtmp
│ └── PBMC.xls
├── step3
│ ├── counts.xls
│ ├── detail.xls
│ ├── filtered_feature_bc_matrix
│ │ ├── barcodes.tsv.gz
│ │ ├── features.tsv.gz
│ │ └── matrix.mtx.gz
│ ├── raw_feature_bc_matrix
│ │ ├── barcodes.tsv.gz
│ │ ├── features.tsv.gz
│ │ └── matrix.mtx.gz
│ └── umi.xls
└── step4
├── biotype_FindAllMarkers.xls
├── FeatureScatter.png
├── FindAllMarkers.xls
├── lncgene_FindAllMarkers.xls
├── mito_quantile.xls
├── nCount_quantile.xls
├── nFeature_quantile.xls
├── PBMC.rds
├── resolution.xls
├── top10_heatmap.png
├── tsne.png
├── tsne_umi.png
├── tsne_umi.xls
├── umap.png
└── VlnPlot.png- The file "PBMC_report.html" is a sample HTML report of the sample.
- The file "PBMC_summary.csv" contains quality control information of the sample in CSV format.
- The file "step3/filtered_feature_bc_matrix" is the filtered expression matrix after applying filtering steps.
- The file "step4/PBMC.rds" is an RDS file containing the matrix that has been processed using Seurat.
Algorithms Overview
step1: barcode/UMI extraction
SeekSoulTools is able to extract the barcode and UMI sequences based on different Read1 structures. The pipeline processes the barcodes and filters Read1 and its corresponding Read2, and an updated fastq file is generated at the end of step 1.
Structure design and description
Barcode and UMI descriptions: Describing the basic structure of Read1 using letters and numbers, where the letters represent the meaning of the nucleotides and the numbers represent the length of the nucleotides.
B: barcode bases L: llinker bases U: UMI bases X: other arbitrary bases used as placeholders
The Read1 structure of the FAST product is B17U12:
Workflow
Barcode and linker correction:
After determining the starting position of the barcode, the corresponding sequence is extracted based on the structural design. When the extracted barcode sequence is found in the whitelist, it is considered a valid barcode and the read count with valid barcodes is recorded. When the barcode is not found in the whitelist, it is considered an invalid barcode.
During sequencing process, there is a certain probability that sequencing error occurs. With the presense of a whitelist, SeekSoulTools are able to do barcode correction. When correction is enabled, if sequences that are one base differ (one humming distance apart) from the invalid barcode appear in the whitelist, we will consider the following circumstances:
- If there is one and only sequence exists in the whitelist, we will correct the invalid barcode to the barcode in the whitelist.
- If multiple sequences exist in the whitelist, we will correct the invalid barcode to the sequence with the highest read support.
Adaptors and polyA sequence trimming
In transcriptome, polyA tail and Adapter sequences introduced during library preparation, may appear at the end of Read2.We remove these contaminating sequences and make sure the trimmed Read2 length is greater than the minimum length for accurate alignment afterward. If the trimmed Read2 length is less than the minimum length, we consider the read to be invalid.
After the processing procedure described above, the metrics is shown below:
- total: Total reads
- valid: Number of reads without correction and number of successfully corrected reads
- B_corrected: Number of successfully corrected reads
- B_no_correction: Number of reads with incorrect barcodes
- trimmed: Number of reads that have been trimmed
- too_short: Number of reads that are shorter than 60bps after trimming
Number of reads in the updated FASTQ file: total_output = valid - too_short
step2: Alignment
Sequence Alignment
- The processed reads1 and reads2, totaling 8 million reads, were aligned to the reference genome of ribosomes using the STAR alignment software. featureCounts was used to assign the aligned reads to genes and calculate the proportions of rRNA and Mt_rRNA in the data.
- STAR was used to align the processed reads1 and reads2 to the reference genome.
- The GTF file was utilized to identify all exon positions of the housekeeping gene ACTB, and the proportion of intervals with coverage exceeding 0.2 times the average depth of ACTB was calculated from the BAM file.
- Based on the GTF file, all exon intervals of the transcripts were converted to BED format, and 10,000 random intervals of transcripts were selected for gene body plotting.
- After the alignment procedure has mapped the reads to the genome, SeekSoulTools uses another software called QualiMap along with a gene annotation transcript file GTF to bucket the reads into exonic, intronic, and intergenic regions.
- Using featureCounts, the reads aligned to the genome were annotated to genes, with different rules such as strand specificity and features used for annotation. When using exon for annotation, a read is annotated to the corresponding gene if over 50% of its bases are aligned to the exon. When using transcripts for annotation, a read is annotated to the corresponding gene if over 50% of its bases are aligned to the transcript.
After the processing procedure described above, the metrics is shown below:
- Reads Mapped to Genome: Fraction of reads that aligned to the genome (including both uniquely mapped reads and multi-mapped reads)
- Reads Mapped to Middle Genebody:The proportion of the transcript covered by the 25%-75% interval in gene body.
- Reads Mapped Confidently to Genome: Fraction of reads that uniquely mapped to the genome
- Fraction over 0.2 mean coverage depth of ACTB gene:The proportion of the ACTB gene length occupied by the interval with an average coverage depth exceeding 0.2 times the average coverage depth of ACTB gene.
- rRNA% in Mapped:The proportion of ribosomal genes in the sequencing data.
- Mt_rRNA% in Mapped:The proportion of mitochondrial ribosomal genes in the sequencing data.
- Reads Mapped to Intergenic Regions:Fraction of reads that mapped to intronic regions
- Reads Mapped to Intronic Regions:Fraction of reads that mapped to intronic regions
- Reads Mapped to Exonic Regions:Fraction of reads that mapped to exonic regions
step3: Counting
UMI counting
SeekSoulTools extracts group of reads that shared the same barcode from output BAM file and counts the number of UMIs annotated to genes and the number of reads corresponding to each UMI.
- Filter out reads whose UMIs consist of repetitive bases. For example, TTTTTTTT.
- If a read has multiple annotations and only one gene annotation is from exon, it is considered a valid read, and all others are filtered.
UMI correction
UMIs may also have sequencing errors during sequencing process. By default, SeekSoulTools uses the adjacency from UMI-tools to correct UMIs.
Image source: https://umi-tools.readthedocs.io/en/latest/the_methods.html
Cell calling
In a cell population, we assume that the mRNA content of cells does not differ significantly. If the mRNA content of a barcode is very low, we consider that barcode might be 'empty', and the mRNA comes from the background. SeekSoulTools uses the following steps to determine whether a barcode has a cell:
- Sort all barcodes in descending order based on their corresponding UMI counts.
- The threshold is calculated by dividing the number of UMIs for the barcode at the 1% position of the estimated cells by 10.
- Barcodes with UMIs greater than the threshold are considered to be cells.
- If the UMI of a barcode is less than the threshold but greater than 300, DropletUtils is used for further analysis. The DropletUtils method first assumes that barcodes with UMI counts below 100 are empty droplets. It then uses the total UMI count for each gene in each droplet as the expected UMI count for that gene in the background RNA expression profile. Next, it performs a statistical test on the UMI counts of each barcode, identifying those with significant differences as cells.
- Those do not meet the above criteria are considered as background.
After the processing procedure described above, the metrics is shown below:
- Estimated Number of Cells: Total number of cells by cell calling
- Fraction Reads in Cells: Fraction of reads after cell calling among all reads used for counting
- Mean Reads per Cell: Average number of reads per cell, Total number of reads/Number of cells after cell calling
- Median Genes per Cell: Median gene count in barcodes after cell calling
- Median UMI Counts per Cell: Median UMI count in barcodes after cell calling
- Total Genes Detected: Number of genes detected in all cells
- Sequencing Saturation: 1 - Total UMI count/Total read count
step4: Downstream analysis
SeekSoulTools perform downstream analysis when we have gene expression matrix from step3.
Seurat analysis
SeekSoulTools use Seurat to calculate the mitochondrial content, number of genes, and UMIs of each cell. After that, the gene expression matrix is normalized, and a subset of features that exhibit high cell-to-cell variation in the dataset is identified. Linear dimensional reduction using PCA is then performed, and the result is passed to t-SNE and UMAP for visualization. A graph-based clustering procedure is then followed, and cells are partitioned into different clusters. Finally, SeekSoulTools finds markers that define clusters via differential expression.
vdj module
NOTE
The vdj module is designed for processing immune receptor data from the SeekOne® DD Single Cell Immune Profiling Kit. It performs:
- V(D)J sequence assembly
- Chain pairing analysis
- Clonotype identification
- Annotation with reference databases
Data Preparation
Download Sample Datasets
Sample Datasets - md5: 3d15fcfdefc0722735d726f40ec4e324 (Species: Human)
wget download method:
wget -c -O vdj_demo.tar "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/vdj_demo.tar"
# decompress
tar xf vdj_demo.tarcurl download method:
curl -C - -o vdj_demo.tar "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/demodata/vdj_demo.tar"
# decompress
tar xf vdj_demo.tarDownload Reference Data
IMPORTANT
The vdj module requires specific reference data for:
- V(D)J gene segments
- Constant region sequences
- Known CDR3 sequences
Download-human-vdj-reference - md5: 5473213ae62ebf35326a85c8fba6cc42
Download-mouse-vdj-reference - md5: 5c7c63701ffd7bb5e6b2b9c2b650e3c2
wget download method:
wget -c -O vdj_GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/vdj_GRCh38_alts_ensembl.tar.gz"
# decompress
tar -zxvf vdj_GRCh38.tar.gz
wget -c -O vdj_GRCm38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/vdj_GRCm38_alts_ensembl.tar.gz"
tar -zxvf vdj_GRCm38.tar.gzcurl download method:
curl -C - -o vdj_GRCh38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/vdj_GRCh38_alts_ensembl.tar.gz"
# decompress
tar -zxvf vdj_GRCh38.tar.gz
curl -C - -o vdj_GRCm38.tar.gz "https://seekgene-public.oss-cn-beijing.aliyuncs.com/software/data/reference/vdj_GRCm38_alts_ensembl.tar.gz"
tar -zxvf vdj_GRCm38.tar.gzRunning
Run Examples
TIP
The vdj module supports different analysis modes:
- Basic mode: Standard V(D)J analysis
- Multi-chain mode: Analysis of cells with multiple chains
- Custom reference mode: Using custom V(D)J references
Example 1: Basic Usage
Set up the necessary configuration files for analysis, including sample data paths, reference data, and output settings:
seeksoultools vdj run \
--fq1 /path/to/vdj_demo/vdj_demo_S1_L001_R1_001.fastq.gz \
--fq2 /path/to/vdj_demo/vdj_demo_S1_L001_R2_001.fastq.gz \
--samplename vdj_demo \
--reference /path/to/vdj_GRCh38 \
--chemistry DDV2 \
--core 4Example 2: Multiple FASTQ Files for One Sample
If a sample has multiple FASTQ datasets, provide all associated FASTQ files:
seeksoultools vdj run \
--fq1 /path/to/vdj_demo_S1_L001_R1_001.fastq.gz \
--fq1 /path/to/vdj_demo_S1_L002_R1_001.fastq.gz \
--fq2 /path/to/vdj_demo_S1_L001_R2_001.fastq.gz \
--fq2 /path/to/vdj_demo_S1_L002_R2_001.fastq.gz \
--samplename vdj_demo \
--reference /path/to/vdj_GRCh38 \
--chemistry DDV2 \
--core 4Parameter Descriptions
IMPORTANT
Key parameters that affect analysis results:
- --chemistry: Must match the kit type used
- --reference: Must be compatible with species
- --chain: Affects which chains are analyzed
- --min-reads: Impacts clonotype identification
| Parameters | Descriptions |
|---|---|
| --fq1 | Paths to R1 fastq files. |
| --fq2 | Paths to R2 fastq files. |
| --samplename | Sample name. A directory will be created with this name in the outdir directory. Only digits, letters, and underscores are supported. |
| --outdir | Output directory. Default: ./ |
| --reference | Path to the V(D)J reference directory. |
| --chemistry | Reagent type. Available options: DDV2 (SeekOne® DD Single Cell Immune Profiling Kit). |
| --chain | Chain types to analyze. Options: TR (T cell receptor), IG (immunoglobulin), or ALL (both). Default: ALL |
| --min-reads | Minimum number of reads required to call a clonotype. Default: 2 |
| --core | Number of threads used for analysis. |
Output Description
Below is the output directory structure:
.
├── vdj_demo_report.html
├── vdj_demo_summary.csv
├── vdj_demo_summary.json
├── filtered_contig.fasta
├── filtered_contig.fasta.json
├── filtered_contig_annotations.csv
├── clonotypes.csv
├── consensus.fasta
├── consensus_annotations.csv
└── all_contig.fastaKey output files:
vdj_demo_report.html: Sample HTML report with analysis resultsvdj_demo_summary.csv: Quality control information in CSV formatfiltered_contig_annotations.csv: Detailed V(D)J annotations for each contigclonotypes.csv: Clonotype information including frequencies and CDR3 sequences
Processing Steps
Step 1: Barcode and UMI Processing
CAUTION
During barcode and UMI extraction:
- Monitor extraction quality metrics
- Check for high rates of barcode correction
- Verify trimming statistics
SeekSoulTools processes barcodes and UMIs according to the chemistry specification, filtering and correcting as needed.
Step 2: V(D)J Assembly
NOTE
The assembly process includes:
- Read preprocessing and quality filtering
- De novo assembly of contigs
- V(D)J annotation of contigs
- Consensus sequence generation
The software uses a de novo assembly approach to reconstruct full-length V(D)J sequences:
- Clusters reads by barcode and UMI
- Performs local assembly within each cluster
- Annotates V, D, J genes and CDR3 regions
- Generates consensus sequences for each clonotype
Step 3: Clonotype Calling
IMPORTANT
Clonotype identification considers:
- CDR3 nucleotide sequence
- V(D)J gene usage
- Chain pairing information
- Read support and quality metrics
The software groups cells into clonotypes based on:
- Identical CDR3 nucleotide sequences
- Same V and J gene usage
- Consistent chain pairing (for multi-chain analysis)
Step 4: Quality Control and Filtering
WARNING
Quality control steps include:
- Removing low-quality assemblies
- Filtering chimeric sequences
- Validating CDR3 sequences
- Checking chain pairing validity
Quality metrics available after processing:
- Number of cells with productive V(D)J sequences
- Clonotype diversity metrics
- Chain pairing statistics
- Assembly quality scores
Release Notes
v1.2.2
- Added vdj module for immune repertoire analysis
- Enhanced multi-chain analysis capabilities
- Improved clonotype identification accuracy
- Added detailed V(D)J assembly metrics
- Updated report format with chain pairing visualization
v1.2.1
- Updated report style
- Added SP1, SP2, and TSO adapter trimming
- Added addtag tool for BAM files
- Enhanced support for non-standard GTF files
- Fast module now supports species beyond human and mouse
v1.2.0
- Added output of Read1 FASTQ file after removing barcode and UMI sequences
- Added fast analysis module
- Implemented UMI-tools correction method
- Updated multi-gene read assignment rules: valid when unique exon annotation exists
v1.0.0
- Initial release
utils module
addtag
NOTE
The addtag tool is used to:
- Add barcode and UMI tags to BAM files
- Facilitate visualization in genome browsers
- Enable advanced analysis of single-cell data
Run Example
Set up the necessary configuration files for analysis, including the sample's BAM file and the umi.xls file in the step3 directory:
seeksoultools utils addtag \
--inbam step2/featureCounts/Samplename_SortedByName.bam \
--umifile step3/umi.xls \
--outbam Samplename_addtag.bamParameter Descriptions
| Parameters | Descriptions |
|---|---|
| --inbam | Input BAM file from step2/featureCount directory. |
| --outbam | Output BAM file path with added tags. |
| --umifile | Input UMI file path (step3/umi.xls). |
FAQ
How to build reference genome?
For reference genome construction, please refer to How to build reference genome?